
| Version 1 (modified by , 16 years ago) (diff) |
|---|
Documentation
Introduction
SET is an open source tool for syntax analysis of natural languages. It is based on the principle of detection of important patterns in the text and incremental segmentation of the sentence. Its core consists of a set of patterns (or rules) and a parsing engine that analyses the input sentence according to given rules. Currently, SET is distributed with a set of rules for parsing the Czech language, containing about 150 rules. A simple tree viewer for displaying parser output is also present.
==System features ==
The system is able to parse a morphologically tagged sentence in the vertical (BRIEF) format, i.e. one token per line, in word - lemma - tag order. At the time, the morphological tagging must be disambiguated and the tags are expected in the attribute format, as used by the ajka morphological analyser. Examples of correct input files: sentence 1, sentence 2.
As the output, the system returns syntactic information found in the input sentence in several possible formats:
- All patterns found in the input sentence This information is printed on stderr in the form of matched tokens followed by the particular rule. It is indicated by label Match found.
- Best matches The best pattern matches that are selected by the parser ranking functions and that are used for building the output tree. This information is printed on stderr in the form of matched tokens followed by the particular rule as well. It is indicated by label Match selected.
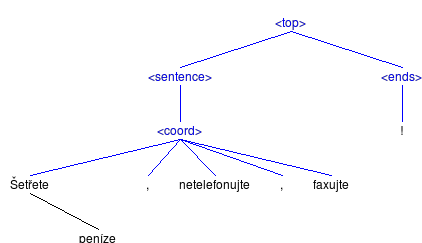
- Hybrid trees Full syntactic trees containing phrasal and dependency elements together. The native output of the parser. In the text form, it is printed on stdout; it can be also displayed in the graphic module.
- Dependency trees Full syntactic trees containing only dependency elements, corresponding to the formalism used by the Institute of Formal and Applied Linguistics in Prague. In the text form, it is printed on stdout; it can be also displayed in the graphic module.
In the text form, the output trees are encoded by set of lines, each of them representing one node of the resulting tree. Each line contains four TAB-delimited fields:
- Node ID (integer number)
- Node label
- Node dependency ID (integer number)
- Dependency type ('p' or 'd', for phrasal or dependency edge)
The latest precision measures (performed with SET version 0.2) show that the precision of the parser dependency output ranges between 75 and 86 percent with respect to the human-anotated Czech corpus data, depending on the particular testing set.
Program usage
The usage of the system is very simple:
./set.py [-gd] <file>
where
-gspecifies graphical tree output (if not given, output tree will display only in the text format that is not readable well),-dswitches to the dependency tree output, instead of hybrid trees, and<file>should contain a tagged Czech sentence in the BRIEF format as showed above and in UTF-8 encoding.
The system performs parsing of the input sentence according to rules defined in the file grammar.set that is present in the installation. The structure of the rules and the process of analysis are further described in the following sections.
Rules structure
Rules syntax
to be described...
SET rules
to be described...
Implementation overview
to be described...
Attachments (9)
-
dp.pdf (395.8 KB) - added by 16 years ago.
Diploma thesis about SET (in Czech)
-
s1.txt (221 bytes) - added by 16 years ago.
Sample sentence 1 (in Czech)
-
kovar_syntakticka_analyza.pdf (113.7 KB) - added by 16 years ago.
Faculty project proposal (in Czech)
- s2.txt (152 bytes) - added by 16 years ago.
- s3.txt (807 bytes) - added by 16 years ago.
- s4.txt (220 bytes) - added by 16 years ago.
- tree1.png (6.9 KB) - added by 16 years ago.
- tree2.png (5.1 KB) - added by 16 years ago.
- tree3.png (3.3 KB) - added by 16 years ago.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Download all attachments as: .zip