
Documentation
Introduction
SET is an open source tool for syntax analysis of natural languages. It is based on the principle of detection of important patterns in the text and incremental segmentation of the sentence. Its core consists of a set of patterns (or rules) and a parsing engine that analyses the input sentence according to given rules. Currently, SET is distributed with a set of rules for parsing the Czech language, containing about 80 rules. A tree viewer for displaying parser output is also present.
System features
The system is able to parse a morphologically annotated sentence in the vertical (or BRIEF) format, i.e. one token per line, in word - lemma - tag order. Ambiguous comma-delimited lemmas and tags are allowed in the input. The tags can be either in the attribute format, as used by the ajka morphological analyser, or in the positional format, as described here (in this case, the --postags switch needs to be used). Examples of correct input files: example 1, example 2, example 3, example 4 (in Czech). Vertical files containing more sentences can also be handled: in this case, the <s> tag is to be used as sentence delimiter.
As the output, the system returns syntactic information found in the input sentence in several possible formats:
- All patterns found in the input sentence This information is printed on stderr in the form of matched tokens followed by the particular rule. It is indicated by label Match found.
- Best matches The best pattern matches that are selected by the parser ranking functions and that are used for building the output tree. This information is printed on stderr in the form of matched tokens followed by the particular rule as well. It is indicated by label Match selected.
- Hybrid trees Full syntactic trees containing phrasal and dependency elements together. The native output of the parser. In the text form, it is printed on stdout; it can be also displayed in the graphic module.
- Dependency trees Full syntactic trees containing only dependency elements, corresponding to the formalism used by the Institute of Formal and Applied Linguistics in Prague. In the text form, it is printed on stdout; it can be also displayed in the graphic module. See the dependency relations labels
- Phrasal trees Full syntactic trees in the constituent format. In the text form, it is printed on stdout in two possible codings; it can be also displayed in the graphic module.
- Collocations Pairs of words in dependency relations. Pairs of lemmas and tags are also output.
- Phrases Word chunks that form phrases in the sentence. These can be output in two possible formats.
- Graphical output Module for comfortable viewing all types of the output trees is available. It provides also possibility to export the resulting tree into several graphical formats.
The output trees in the text form are encoded by set of lines, each of them representing one node of the resulting tree. Each line contains four TAB-delimited fields:
- Node ID (integer number)
- Node label
- Node dependency ID (integer number)
- Dependency type ('p' or 'd', for phrasal or dependency edge)
Phrasal trees can also be printed in the "LAA" format (using the --laa switch) that enables the trees to be compared using the Leaf Ancestor Assessment metric, as described here.
Program usage
The program can be used from the command line as follows:
./set.py [OPTIONS] file
where file has is tagged sentence in vertical or BRIEF format as shown above and OPTIONS can be as follows:
-
-ggraphic output -
-ddependency output (not compatible with-pand--laa) -
-pphrasal trees output -
-cuse collocation data in probabilistic ranking of matches -
--laaphrasal trees output in format usable for tree comparison using the Leaf Ancestor Assessment program by Geoffrey Sampson -
--coutoutput in form of collocations (not compatible with-p,-dand--laa) -
--phrasesoutput in form of phrases -
--marxoutput phrases in an alternative format -
--postagsuse Prague positional tags in input -
--versionshow the version of the program
Requirements:
- Python 2.5
- python-qt4 (for graphical output only)
- pyqt4-dev-tools (for graphical output only)
The system performs parsing of the input sentence according to rules defined in the file grammar.set that is present in the installation. The structure of the rules and the process of analysis are further described in the following sections.
Rules structure
Rules syntax
A general format of syntax rule is as follows:
TMPL: <template> <action list>
The template cannot be wrapped into several lines, whereas the action list can be wrapped before the action name (so that newline always starts with an action name).
A template is a sequence of following types of tags describing a matching text segment:
An action lists is a sequence of an arbitrary number of actions.
Rules are divided into three sections marked by corresponding headers:
::: relative clauses :::-- rules for detecting relative clauses. When a relative clause is found, its tokens are temporarily deleted from the rest of the sentence and the analysis is launched once again. The purpose of this is being able to detect relationships across inserted relative clauses, such as in Ženy, které se smály, se smát přestaly.::: coordinations :::-- rules for detecting coordinations. If two coordinations are found next to each other with one common token, such as in cars, bikes and motorbikes, they are both used (under the other two headers, this would be a conflict and only one of the matches would be used) and they are merged together, under the phrasal token of the coordination evaluated as the last one.::: dependencies :::-- rules for detecting and marking binary dependency relations. Each rule under this header must use theDEPaction, otherwise it will be ignored; and only the first token marked by the actionMARKis considered.
SET default rules
For current rules used in the SET system, please refer to the grammar.set definition file in the source package. Each rule is commented by an example of its usage.
Implementation overview
The SET system consists of several Python modules:
grammar-- loading, organizing and parsing of rules sets, definition of theRuleaGrammarclass.token-- definition of theTokenclass (and its derivatives) representing a single word/token.segment-- input parsing, definition of theSegmentclass representing the input sentence (a list ofTokenobjects).matcher-- definition of theMatchandMatcherclass. AMatchobjects represents a rule realization, whereasMatchersearches for possible matches on a given segment.parser-- implements the parsing procedure itself (Parserclass) including ranking functions.settings-- contains global settings of the parser.vertical_processor-- implements processing vertical files with more sentences.collocations-- implements searching for collocations that is used in the best matches selection process.TreeViewer-- implements displaying graphical output of trees.tree_view-- old, simple module for displaying graphical output of trees.utils-- contains several helper functions.set-- represents the main module.compare_dep_trees-- helper script for evaluation of the parsing results.
Screenshots
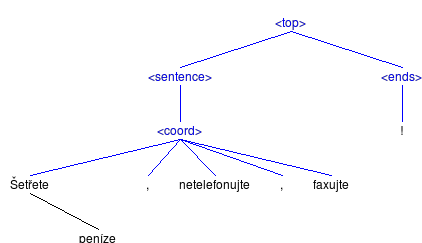
Comparison of constituent(left), hybrid (middle) and dependency (right) output trees for the input sentence: Šetřete peníze, netelefonujte, faxujte! (Save money, do not phone, fax!)



Attachments (9)
-
dp.pdf (395.8 KB) - added by 16 years ago.
Diploma thesis about SET (in Czech)
-
s1.txt (221 bytes) - added by 16 years ago.
Sample sentence 1 (in Czech)
-
kovar_syntakticka_analyza.pdf (113.7 KB) - added by 16 years ago.
Faculty project proposal (in Czech)
- s2.txt (152 bytes) - added by 15 years ago.
- s3.txt (807 bytes) - added by 15 years ago.
- s4.txt (220 bytes) - added by 15 years ago.
- tree1.png (6.9 KB) - added by 15 years ago.
- tree2.png (5.1 KB) - added by 15 years ago.
- tree3.png (3.3 KB) - added by 15 years ago.
{kind=link}
{kind=link}
{kind=link}
Download all attachments as: .zip