
What do we work on in the NLP Centre?
Try some of our language tools:
- The Online Language Handbook
- CZ accent
for adding diacritics - Ajka
morphological analyzer - Synt and SET
syntactic analyzers - Language Services
Language Services - Aggregate API
The Natural Language Processing Centre focuses on obtaining practical results in the field of language modeling, information technologies, and linguistics. Results of the projects are frequently published at various conferences, the NLP Centre also cooperates with similarly oriented institutes in Czech Republic and abroad, and offers students the possibility to participate in student exchange with partner universities abroad.
More detailed information follows below, grouped into chapters according to their topic:
Language Modeling
Language modeling is the prevalent approach to NLP. Thanks to huge text data, language models accurately represent natural languages and can:
- classify tokens or sequences of tokens,
- predict new tokens based on a sequence of previous words.
Language models are used in natural language generation (NLG), text summarization, sentiment analysis, named entity recognition, and many other NLP tasks.
BenCzechMark
NLPC participates in the project BenCzechMark, which aims to provide a universal large language model benchmark for Czech. The project is a joint work of Brno Technology University, Faculty of Informatics, Mendel University, and other institutions.
Our contribution was to provide benchmark tasks for:
- Propaganda text annotation
- SQAD - question answering dataset
- Umime.to assessments
- natural language inference
The BenCzechMark leaderboard is available at https://huggingface.co/spaces/CZLC/BenCzechMark.
Slama
Is it possible to train a language model from scratch? Yes. Check Slama - Slavic Large Language Model: RASLAN 2024 paper
Corpora

A corpus is a collection of text data in electronic form. As a significant source of linguistic data, corpora make it possible to investigate many frequency-related phenomena in language, and nowadays, they are an indispensable tool in NLP. In addition to corpora containing general texts, corpora for specific purposes are also produced, such as annotated, domain-specific, spoken, or error corpora.
Corpora are the core technology for language modeling. They are also used for research in natural language grammars. They are further helpful when developing a grammar checker, choosing entries for a dictionary, or as a data source for automatic text categorization based on machine learning. Parallel corpora comprise identical texts in various languages. They are used especially in word sense disambiguation and machine translation.
Nowadays, the main source of corpus texts is the World Wide Web. To obtain quality data on a larger scale, pre-processing tools for filtering undesired content need to be used: notably the jusText tool for removing boilerplate, the onion tool for removing duplicate text parts, or the chared utility for detecting text encoding. The popular gensim framework for extracting semantic topics from documents is very useful.
The NLP Centre has produced a complete set of tools for creating and managing corpora, the Corpus Architect. It can store and manage corpora containing 100+ billion word tokens.

Related projects:
Dictionaries

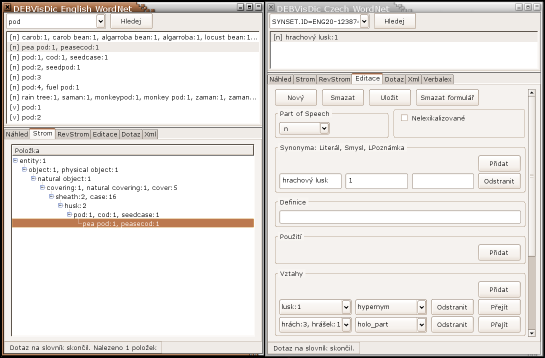
Dictionaries have always been a fundamental part of every linguist's basic equipment. However, handling paper dictionaries is rather inconvenient. Therefore, one of the first projects of the NLP Centre was to digitize classic dictionaries of Czech and develop a set of advanced tools for processing lexicographic data, a so-called lexicographer's workbench. This term refers to a system that enables each expert user to easily access various linguistic resources and provides them with an application interface for searching and editing data.
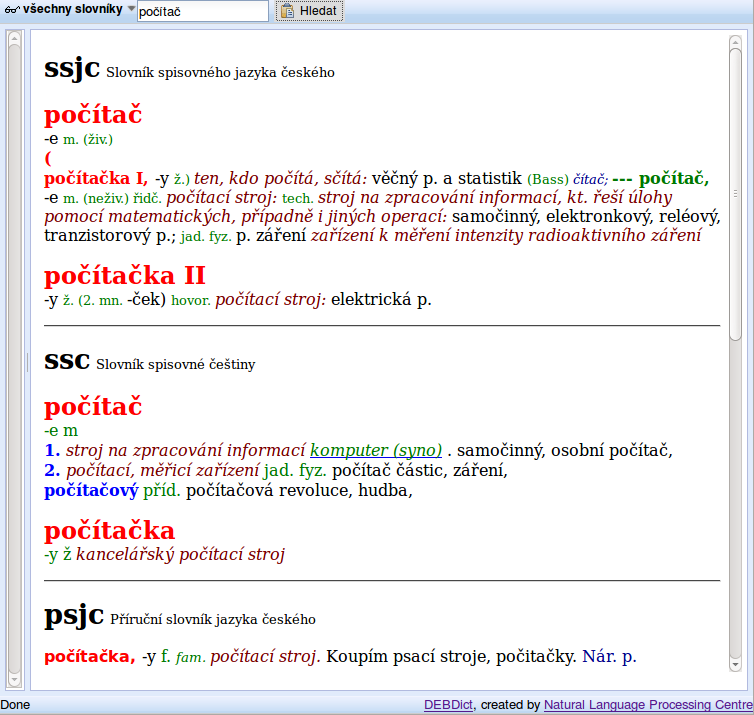
One of our projects related to dictionaries is the development of the DEB platform, offering all the above mentioned features, thanks to its client-server architecture. One of the client applications is the DEBDict dictionary viewer, which contains apart from digitized dictionaries also several encyclopediae, and an onomastic and phraseological dictionary. Applications for DEB are developed in the XUL language and are available as extensions for the Firefox web browser.
Related projects:
Morphology

Morphological analysis gives a basic insight into natural language by studying how to distinguish and generate grammatical forms of words arising through inflection (ie. declension and conjugation). This involves considering a set of tags describing the grammatical categories of the word form concerned, most notably, its base form (lemma) and paradigm. Automatic analysis of word forms in free text can be used for instance in grammar checker development, and can aid corpus tagging, or semi-automatic dictionary compiling.
The NLP Centre has produced a general morphological analyzer for Czech, ajka, which covers vocabulary of over 6 million word forms. It further served as a base for a similar analyzer for Slovak, the fispellgrammar-checker, the czaccent converter of ascii text to text with diacritics, and an interactive interface for the IM Jabber protocol.
Related projects:
Syntactic Analysis

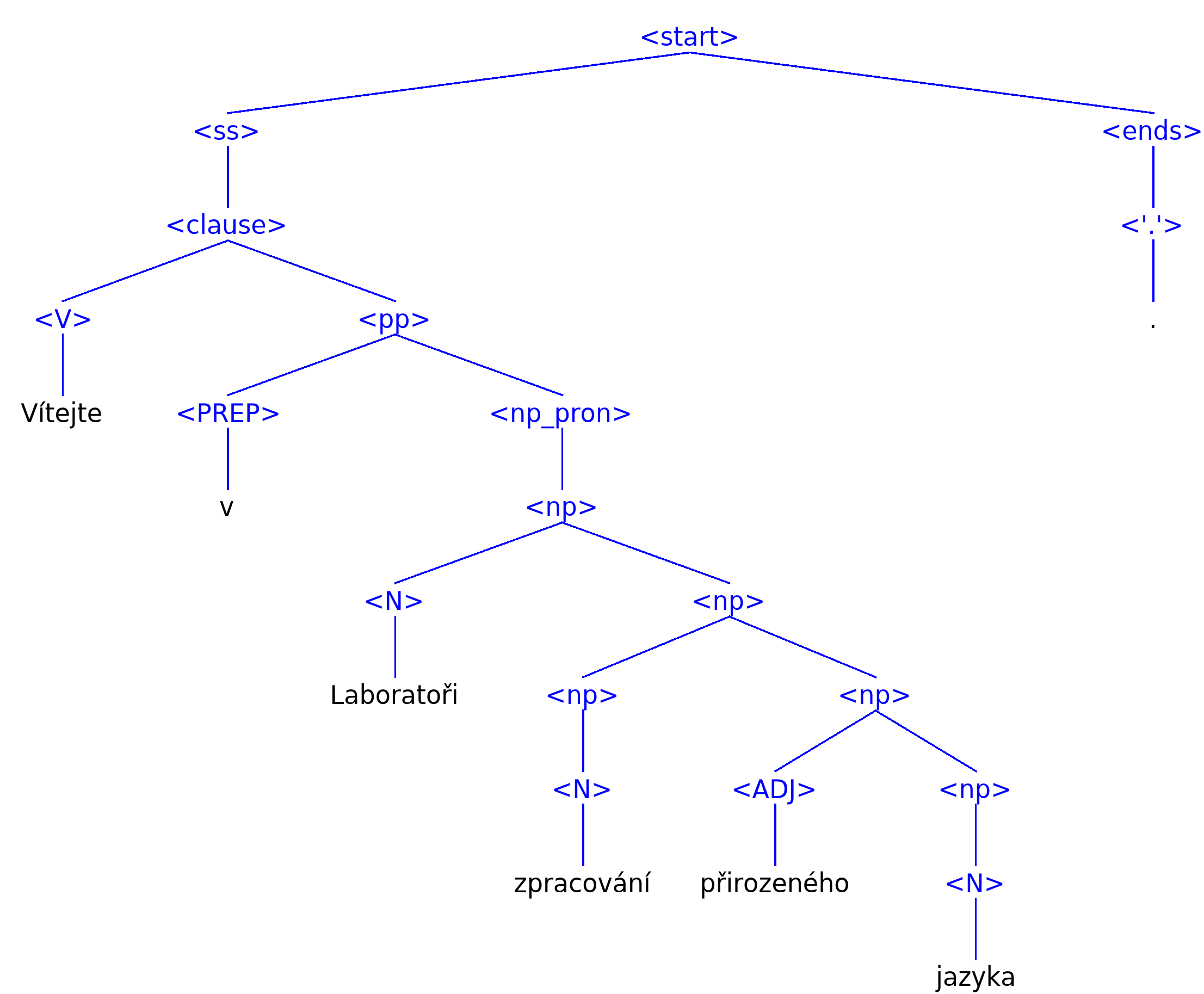
The goal of syntactic analysis is to determine whether the text string on input is a sentence in the given (natural) language. If it is, the result of the analysis contains a description of the syntactic structure of the sentence, for example in the form of a derivation tree. Such formalizations are aimed at making computers "understand" grammar of natural languages. Syntactic analysis can be utilized for instance when developing a punctuation corrector, dialogue systems with a natural language interface, or as a building block in a machine translation system. Czech is a language exhibiting rich inflection and free word order and thus belongs to the languages that are very hard to analyze, as it requires more grammar rules than most other languages.
The NLP Centre is developing several syntactic analyzers. The synt syntactic analyzer is based on a handcraftedCzech meta-grammar enhanced by semantic actions and contextual constraints. SET is a popular lightweightsyntactic analyzer based on set of patterns. Both synt and SET perform syntactic analysis of Czech sentences with an accuracy close to 90%. For educational purposes we have a simple syntactic analyzer Zuzana.
Related projects:
Semantics

Semantic and pragmatic analysis make up the most complex phase of language processing as they build up on results of all the above mentioned disciplines. The ultimate touchstone on this level is machine translation, which hasn't been implemented for Czech with satisfactory results yet.
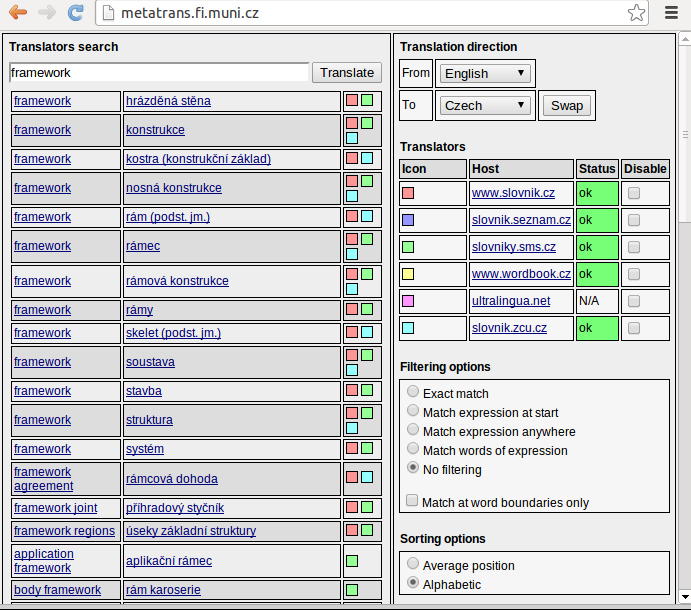
One of the long-term projects of the NLP Centre is the use ofTransparent Intensional Logic (TIL) as a semantic representation of knowledge and subsequently as a transfer language in automatic machine translation. At the current stage, it is realistic to process knowledge in a simpler form - considerably less complex tasks have been addressed, such as machine translation for a restricted domain (eg. official documents and weather reports), or semi-automatic machine translation between close languages. The resources exploited in these applications are corpora, semantic nets, and electronic dictionaries.
In the field of representation of meaning and knowledge we shall mention the notable contribution of NLP Centre members to the EuroWordNet? and Balkanet projects, which were aimed at building a multilingual WordNet?-like semantic net.
Related projects:
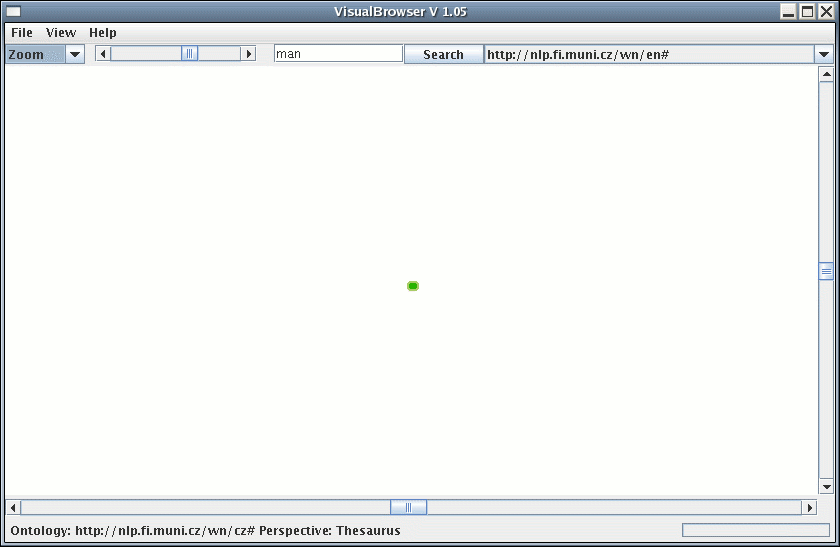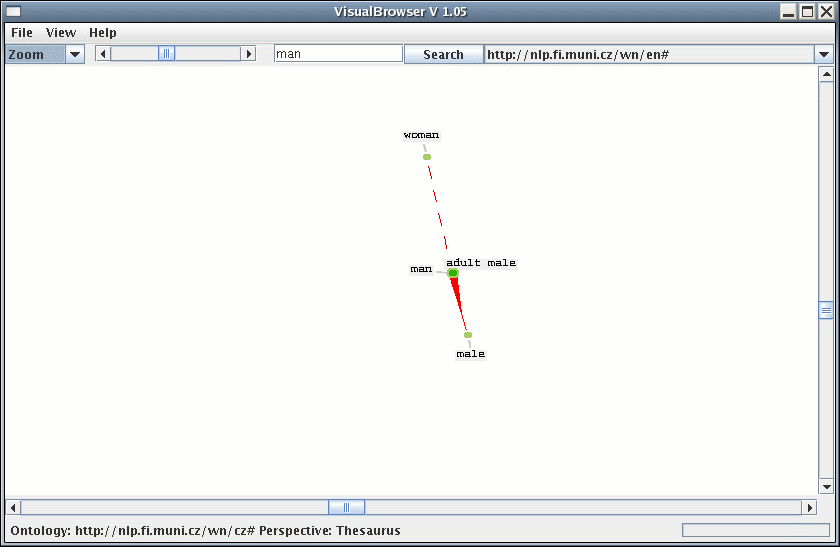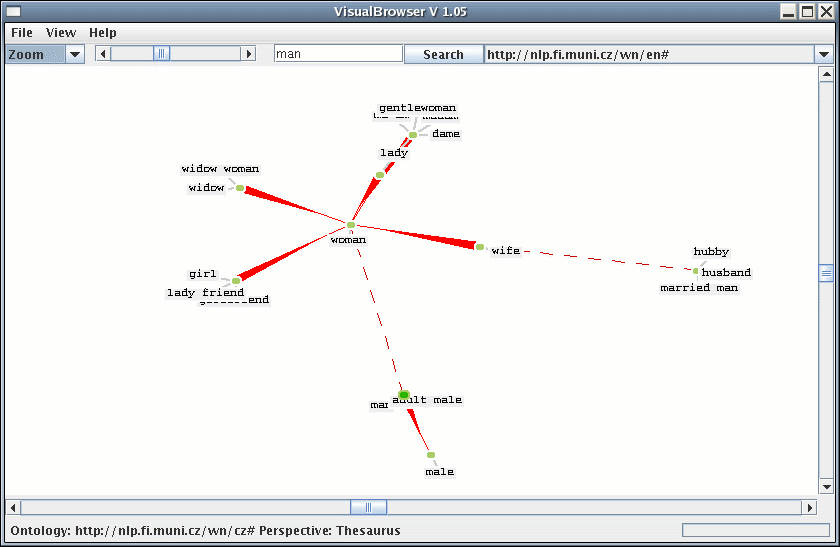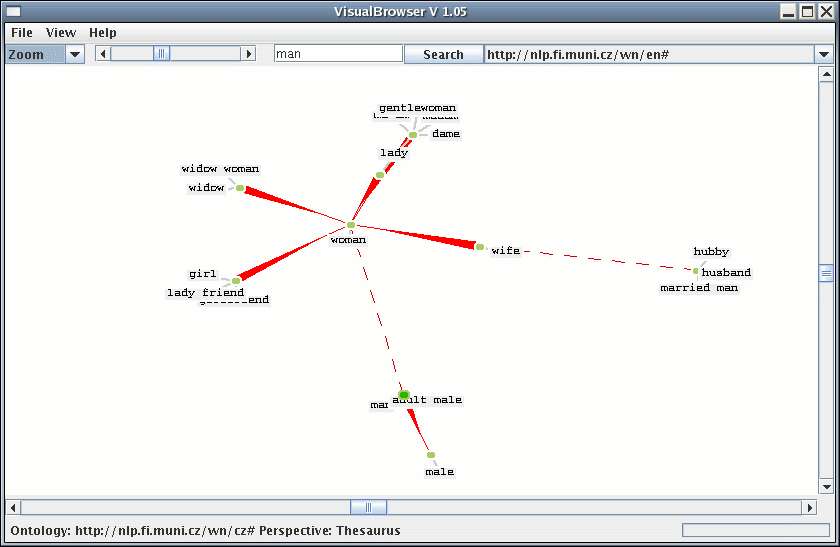
Animated demonstration of the Visual Browser:

Further information
Attachments (8)
- dict2_small.png (40.0 KB) - added by 11 years ago.
- synt_tree.png (74.0 KB) - added by 11 years ago.
- vl_anim.gif (140.5 KB) - added by 11 years ago.
- metatrans.png (77.6 KB) - added by 11 years ago.
- majka_nlpportal.png (54.6 KB) - added by 11 years ago.
- debII_slovniky.png (109.0 KB) - added by 11 years ago.
- corpora.png (88.3 KB) - added by 11 years ago.
- sem1_small.png (82.9 KB) - added by 11 years ago.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Download all attachments as: .zip