
Word Level Analysis
Motivation
Many applications need a tool for “clustering” of word forms appearing in texts:
- chladniček
- chladničky
- chladničkách <=> chladnička
- chladničce
- ...

Usage:
- Indexing, searching, keyword extraction, ...
- And almost all NLP tools
Word Level Processing Data for Czech
For almost 12 M word forms (incl. colloquial forms):
- lemma (canonical form, dictionary form)
- grammatical information: part of speech, number, case etc.
Word form stroj has 3 interpretations:
- lemma stroj, nominative
- lemma stroj, accusative
- noun, masculine animated, singular
- lemma strojit
- verb, 2nd person, singular, imperative mood
Possible Applications
Various types of analyses:
- word form => lemma (many types of searching/indexation)
- nebral => brát/nebrat (úplatky)
- nejstaršího => nejstarší/starý (člověk)
- chladnička => chladničky (as a class)
- bavlna => bavlněný (word derivation)
- word form/lemma + gram. info. => word form
- e.g. salutation generation: pane Procházko
- word form/lemma => all word forms
- word form => lemma + full/partial grammatical information
The analysis is very fast - approx. 1 million word forms per second
Processing Unknown Words
Some word forms in processed texts are unknown:
- terms polydaktylie, neologisms klausoviny, typos bizardního, colloquial words plaťáky, etc.
An ending of the word form is able to determine e.g.
- lemma: klausoviny => klausovina
- grammatical information: bizardního => genitive, etc.
- derivational relations: plaťáky => plaťákový
Texts from a particular domain allows grouping of unknown word forms:
- polydaktylie, polydaktiliích, polydaktylií, ... <=> polydaktylie
- => extension of data or more precise “guessing”
Resolving Ambiguities Using Context
An extreme case Stroj ženu holí.
- Já stroj ženu holí, ty stroj ženu holí, ten stroj ženu holí.
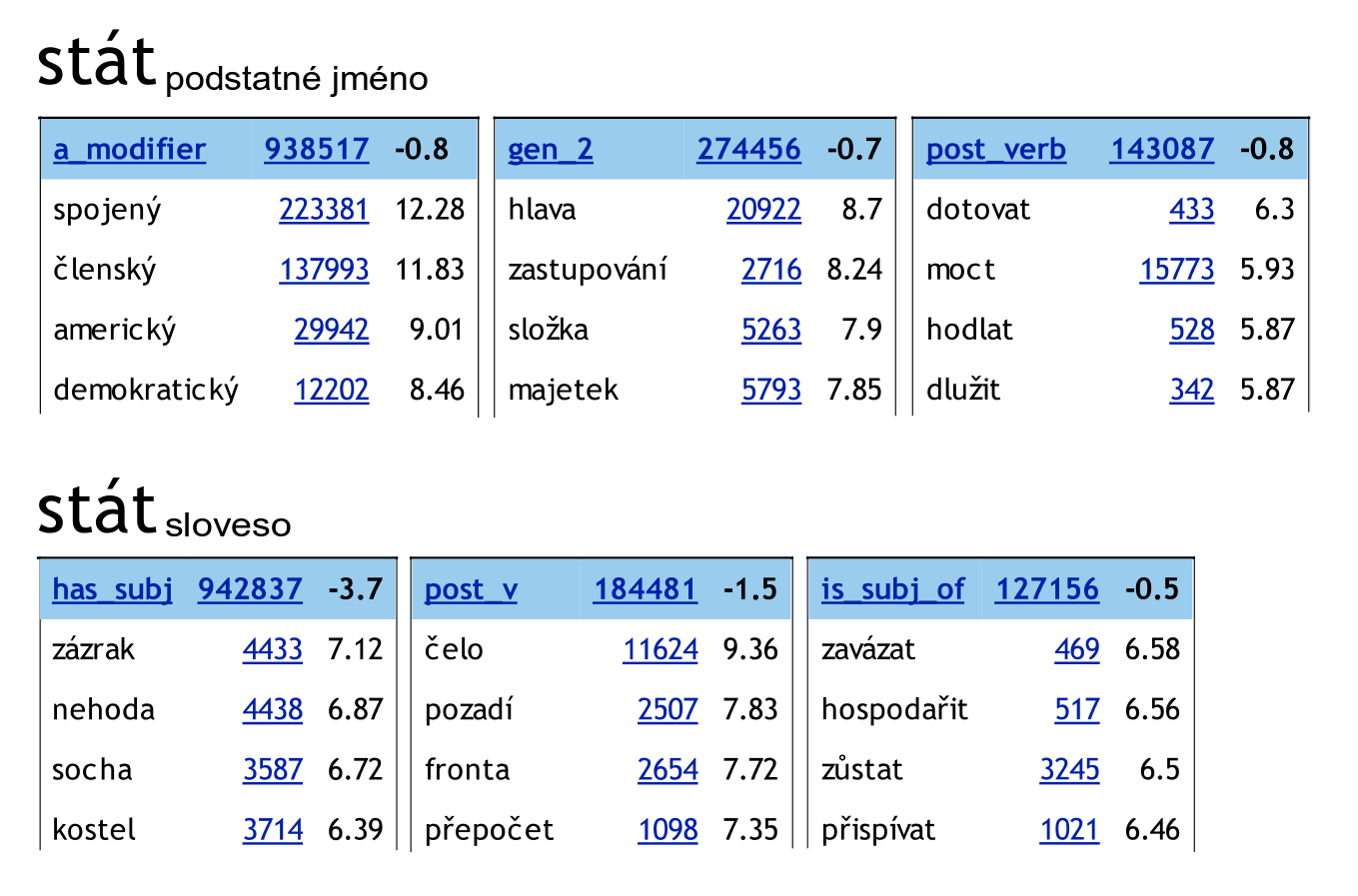
Usual case is e.g. stát
- noun: Stát jsem já.
- verb: Celá továrna musela hodinu stát.
- at the part of speech level, it is a bigger problem for English
The context of the word determines its interpretation
- rules and/or statistical data describe typical contexts of nouns, verbs, etc.
- using such information one can tell that stát is noun/verb
Example of Contexts — Word Sketches

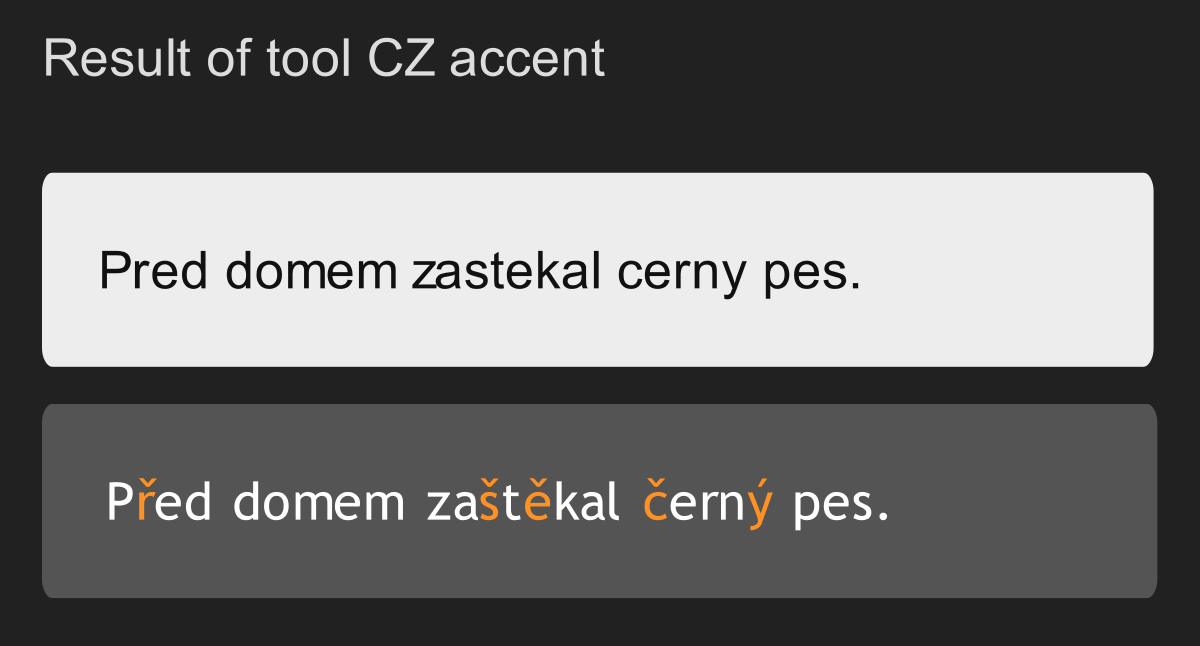
Spellchecking and Diacritics Restoration
Data also allow spellchecking and diacritics restoration:

Universality
All the mentioned processes can be
- tuned for a specific domain
- using texts from this domain
- applied to a language other than Czech
- (Slovak, Polish, German, English, ...)
Latest Applications
Seznam.cz, Yandex.ru, Aukro.cz, Václav Havel Library
- indexing and searching
Information System of Masaryk University
- other universities and schools (FHS UK, JAMU, VŠFS, ...)
- affiliate projects (theses.cz, odevzdej.cz, repozitar.cz)
- indexing, searching and plagiarism detection
“Internetová jazyková příručka”
- online source on Czech orthography and grammar
- NLP Centre data were a starting point for word form tables
Conclusions
Word level processing of texts allows:
- various types of base word determining which forms are to be grouped together
- ambiguity resolution according to the context
- word form generation
- spellchecking, diacritics restoration
The tools/data can be domain specific and for various languages
Attachments (3)
- stat.png (181.4 KB) - added by 11 years ago.
- chladnicka.png (222.6 KB) - added by 11 years ago.
- czAccent.png (49.9 KB) - added by 11 years ago.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Download all attachments as: .zip