
Topic Similarity
Topical Similarity in Digital Mathematics Library

- different machine learning methods as Random Projections, TFIDF word weighting, Latent Semantic Indexing/Analysis, Latent Dirichlet Allocation
- 50,000+ fulltexts on http://dml.cz
Coping with Information Overload by Filtering of Big Data

Life is searching: group similar and narrow focus of search in [your] Big Data.
Similarity types: from plagiarism (similarity on n-grams, narrative similarity, evolved into http://theses.cz) to thematic, topical similarity.
Prehistoric Example: Project Ottuv Slovnk naucny, 1998
Levels of content processing: strings -> words and collocations -> semantics (word meaning) -> information (knowledge).
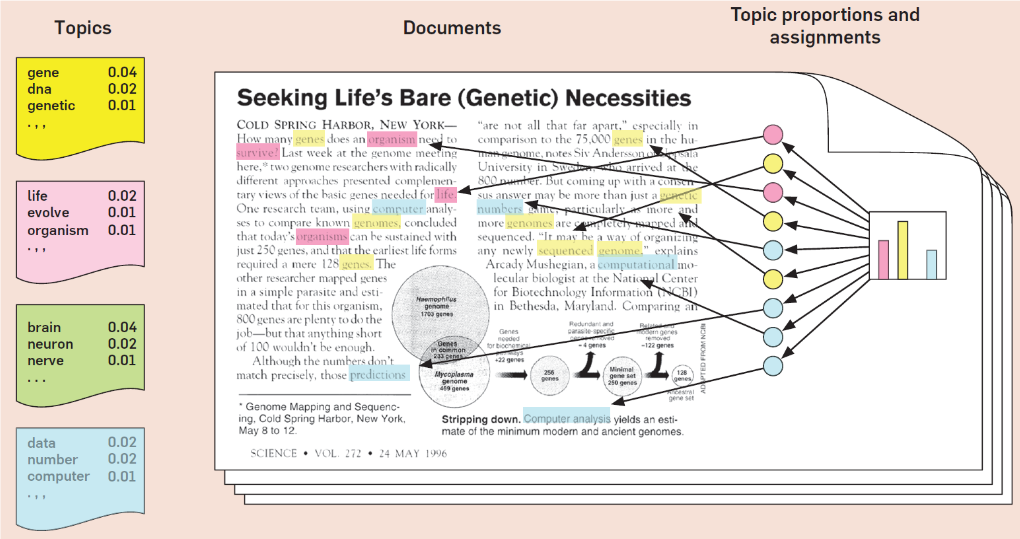
Grabbing the essence (content) of documents: topical modeling.

Leading Edge Example: Automated Meaning Picking from Texts

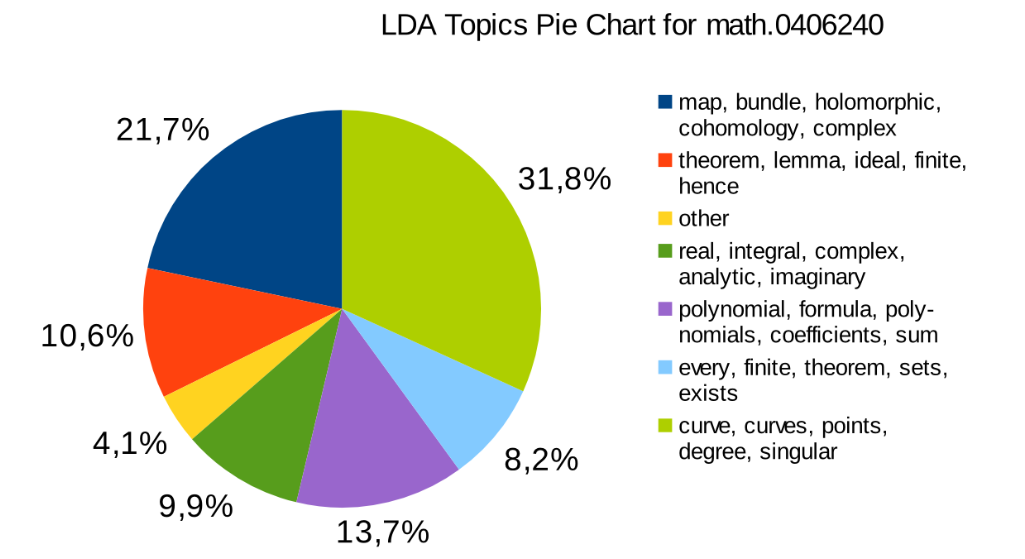
Probabilistic Topical Modeling: Latent Dirichlet Allocation
- topic: weighted list of words
- document: weighted list of topics

- all topics computed automatically from document corpora

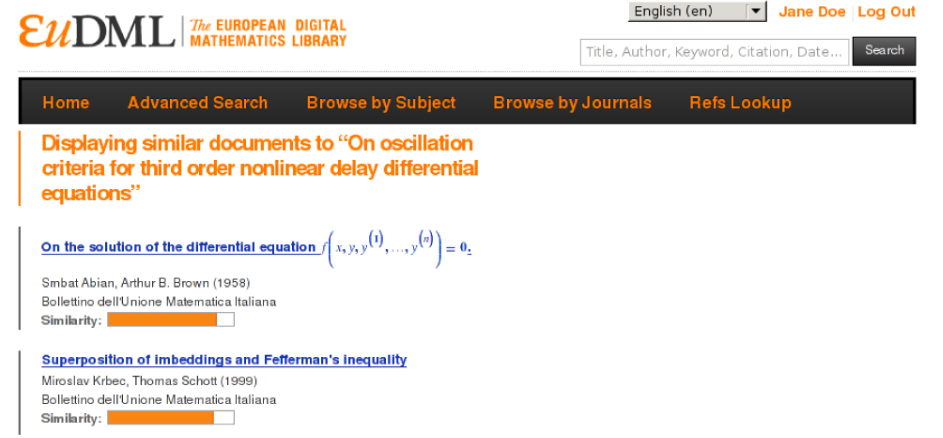
Content Similarity Results in EuDML
Within European Digital Mathematics Library, EuDML, project EU CIP-ICT-PSP we have developed and delivered technology for similarity (gensim), document conversions (Braille) and accessibility (math OCR), NLP content normalization (Mathml2text).

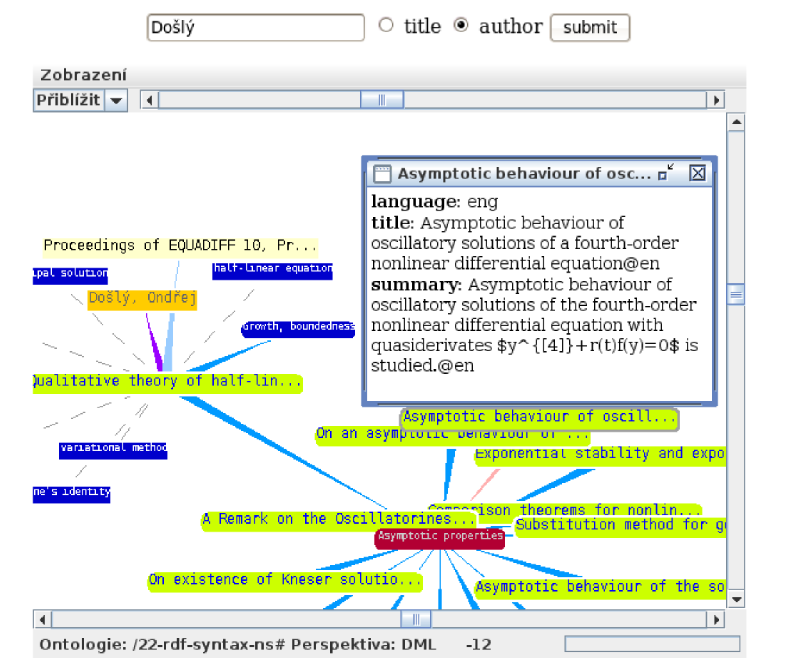
Data Visualization and Representation

Award Winning Topic Similarity Framework gensim
Semantic similarity indexing and search of big (continuous stream of) data. Client (search) and server (indexing) architecture.
Developed by NLP Centre PG student Radim Rehurek (awarded in Ceska hlava competition in 2011).
Leading edge machine learning methods implemented.
Used in 40+ local, EU or worldwide projects.
Typical deployment and ne-tuning scenario: expressing data as words (features) -> conguration of topic modeling of features -> setting of gensim methods and tuning parameters -> usage in an application with proper vizualization interface.
Conclusions
- similarity: plagiarism
- topical modeling
- thematic document ltering
- visualization
- semantic, meaning computations and modeling of natural language texts
Credits: Jiri Franek (illustrations)
Attachments (8)
- sim_articles.png (339.6 KB) - added by 11 years ago.
- search.png (235.0 KB) - added by 11 years ago.
- ottuv_slovnik.png (210.9 KB) - added by 11 years ago.
- lda_topics.png (121.7 KB) - added by 11 years ago.
- topical_mod.png (283.1 KB) - added by 11 years ago.
- allocation.png (104.1 KB) - added by 11 years ago.
- eudml_sim.png (108.1 KB) - added by 11 years ago.
- data_vis.png (142.2 KB) - added by 11 years ago.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Download all attachments as: .zip