
| Version 4 (modified by , 11 years ago) (diff) |
|---|
Processing of Very Large Text Collections
Why to process natural language texts?
- lots of information, growing every day (web)
- need for fast and continuous knowledge mining
- no time for human intervention
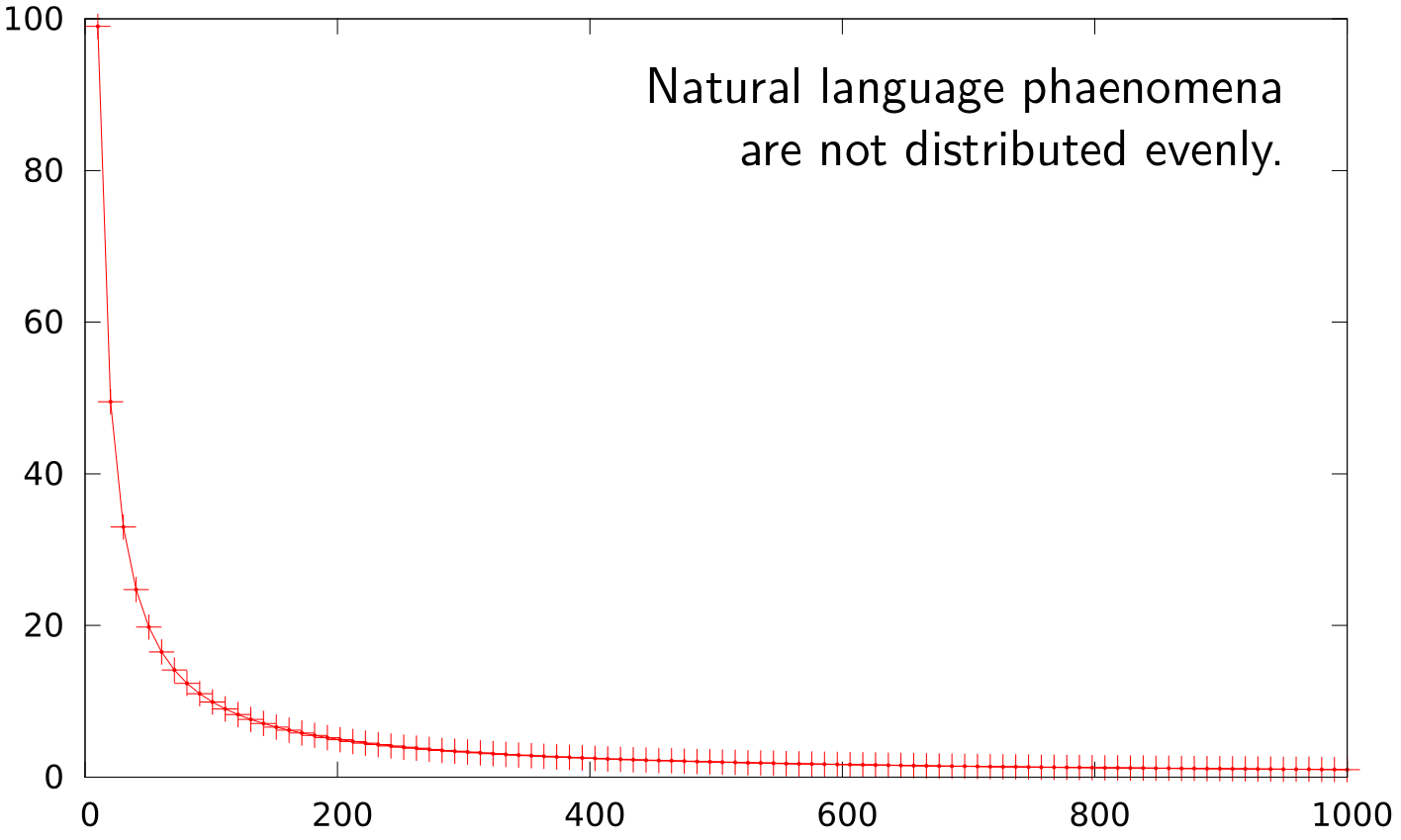
- large data make statistical processing possible
- real data instead of false assumptions
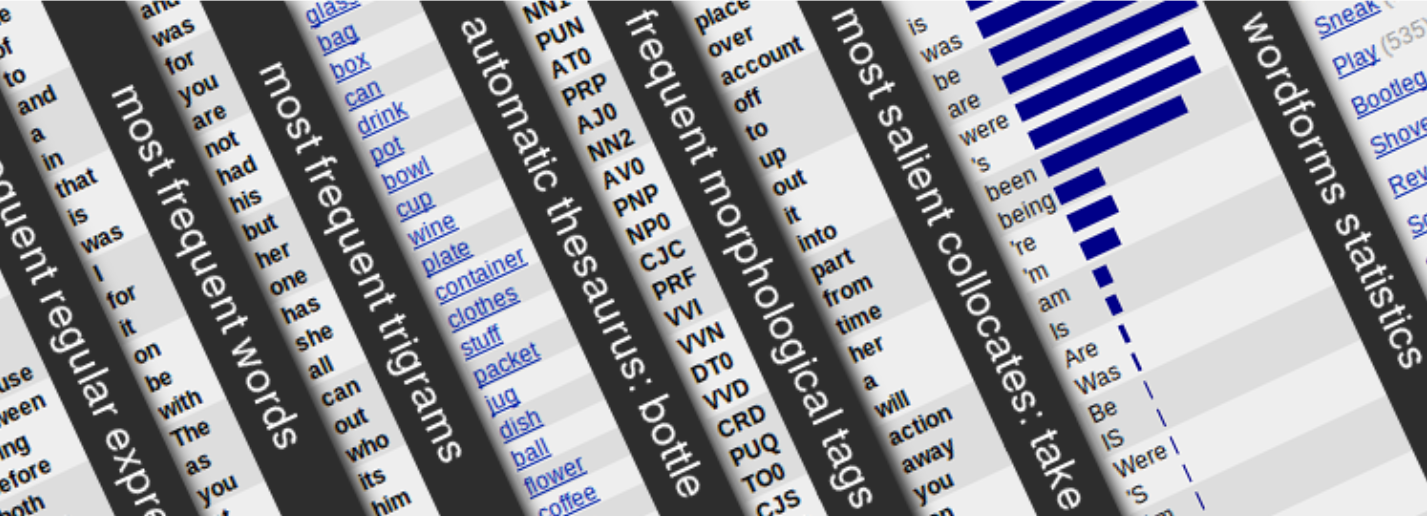
Information in Text

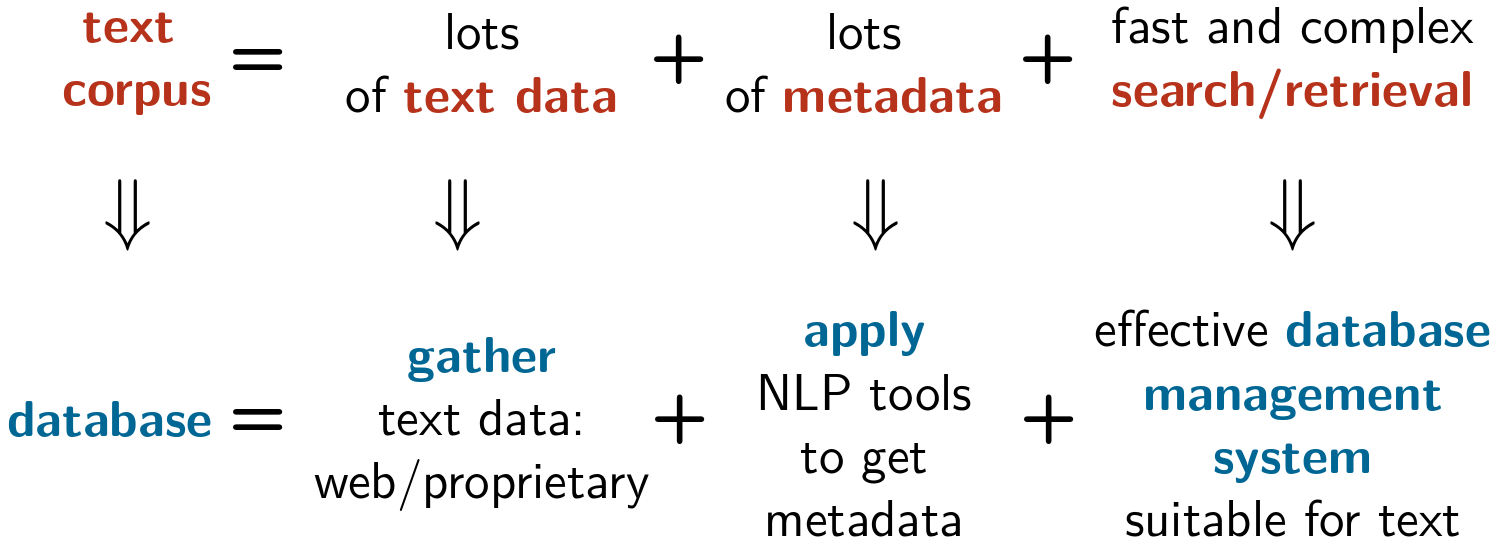
Text collection = a text corpus
- text collection: usually referred to as text corpus
- humanities → corpus linguistics, language learning
- computer science → effective design of specialized database management systems
- applications → usage of any text as information source
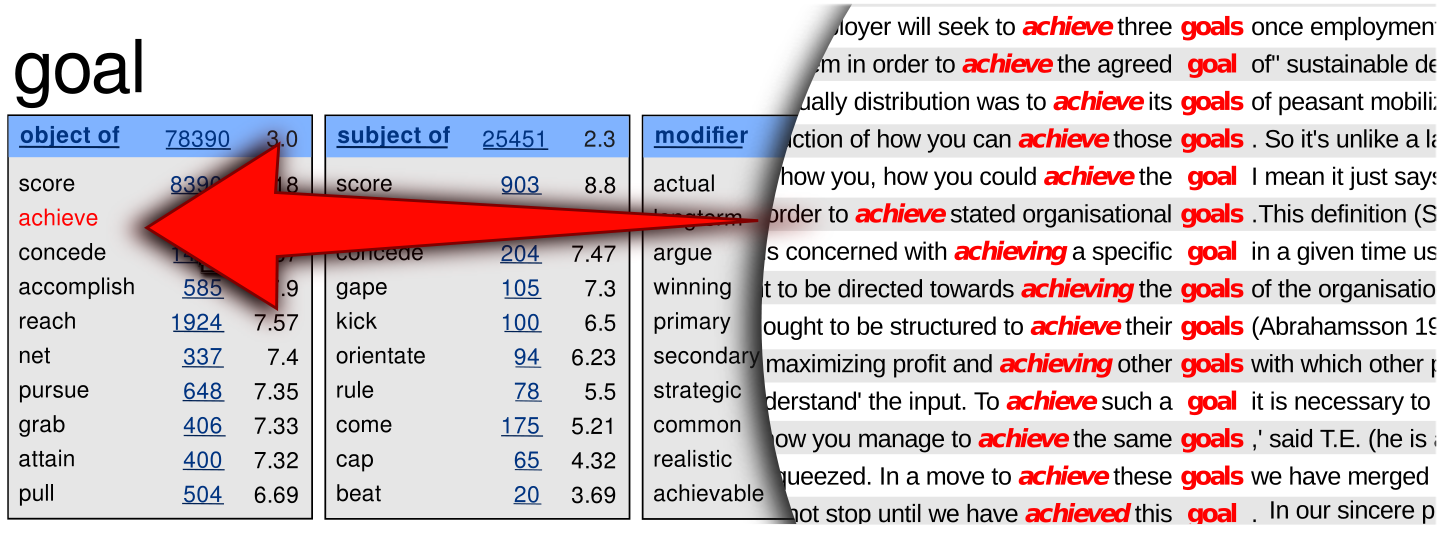
Text Corpora as Information Source

So what is a corpus?

Corpora
- text type
- general language (gather domain independent information: common sense knowledge, global statistics, information defaults)
- domain specific (gather domain specific information: terminology, in-domain knowledge, contrast to common texts)
- timeline
- synchronic: one time period / time span (→ what is up now?)
- diachronic: different time periods / time spans (→ what are the trends?)
- language, written/spoken, metadata annotation type,...
Attachments (10)
- text.png (611.8 KB) - added by 11 years ago.
- goal.png (332.1 KB) - added by 11 years ago.
- what_is_corpus.png (76.0 KB) - added by 11 years ago.
- distribution.png (54.0 KB) - added by 11 years ago.
- corpus_langs.png (225.3 KB) - added by 11 years ago.
- query.png (364.9 KB) - added by 11 years ago.
- comparison.png (148.8 KB) - added by 11 years ago.
- corpus_build.png (471.3 KB) - added by 11 years ago.
- corpus_test.png (141.1 KB) - added by 11 years ago.
- corpora_size.png (26.5 KB) - added by 11 years ago.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}