
Processing of Very Large Text Collections
Why to process natural language texts?
- lots of information, growing every day (web)
- need for fast and continuous knowledge mining
- no time for human intervention
- large data make statistical processing possible
- real data instead of false assumptions
Information in Text

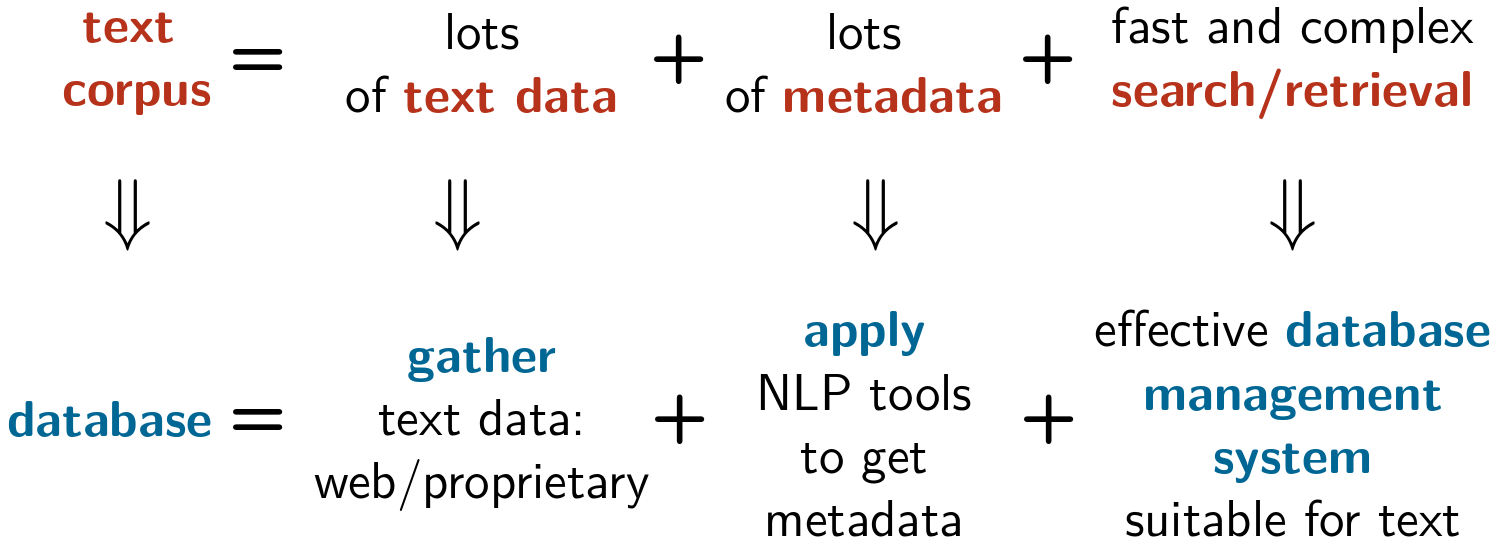
Text collection = a text corpus
- text collection: usually referred to as text corpus
- humanities → corpus linguistics, language learning
- computer science → effective design of specialized database management systems
- applications → usage of any text as information source
Text Corpora as Information Source

So what is a corpus?

Corpora
- text type
- general language (gather domain independent information: common sense knowledge, global statistics, information defaults)
- domain specific (gather domain specific information: terminology, in-domain knowledge, contrast to common texts)
- timeline
- synchronic: one time period / time span (→ what is up now?)
- diachronic: different time periods / time spans (→ what are the trends?)
- language, written/spoken, metadata annotation type,...

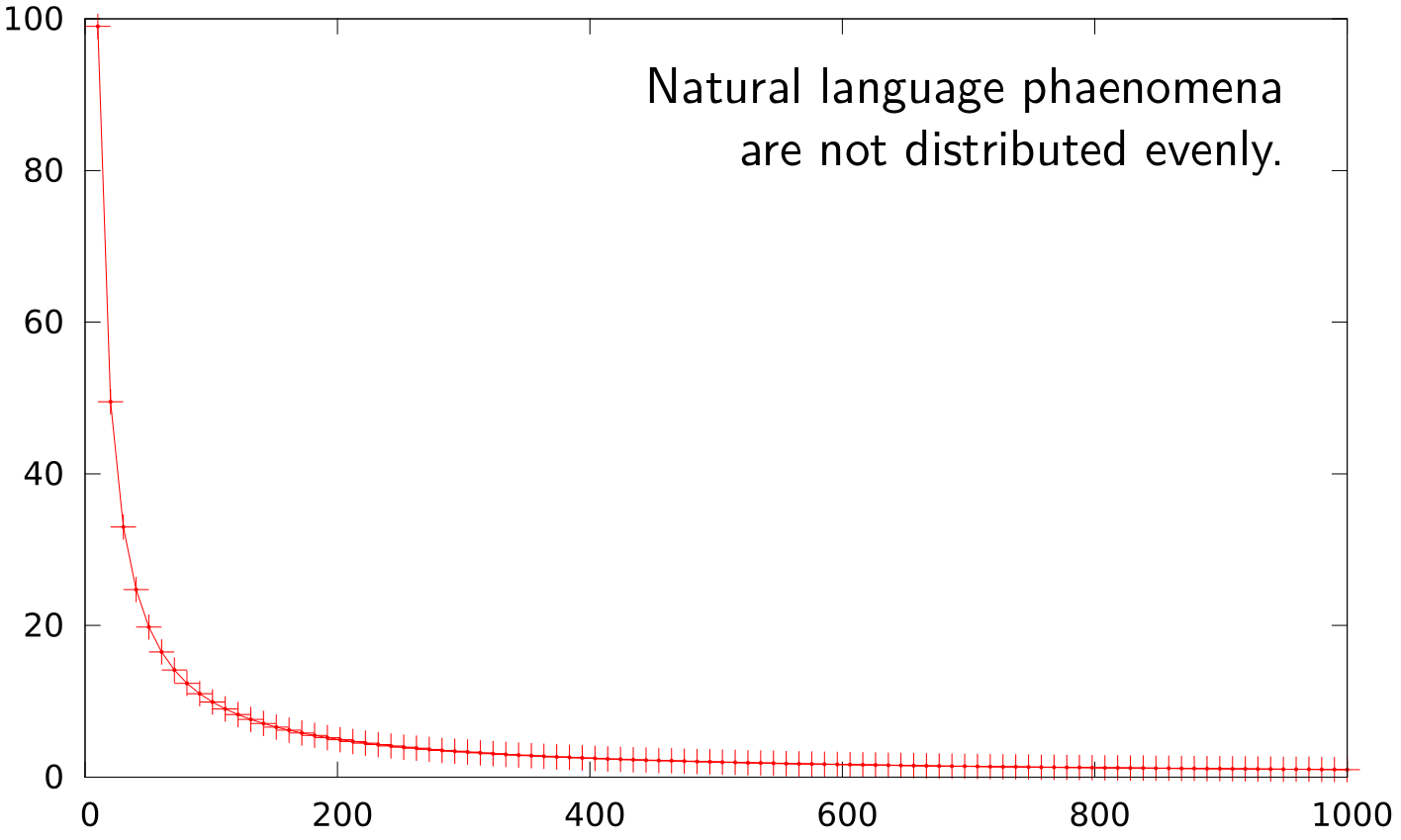
Why does size matter so much?

Corpora now
Corpora at NLP Centre:
- LARGE: billions (~10(10)) of words

- COMPLEX: muti-level multi-value annotation, wide range of languages

A big need for search/retrieval that is:
- INTELLIGENT: complex searching involving large amounts of metadata
- VERY FAST: parallel and distributed processing
- ACCESSIBLE: interfaces for automatic processing via third-party tools
Applications
- information systems (going beyond fulltext search)
- information analytics (opinion mining, marketing assessment)
- intelligent text processing (predictive and adaptive writing, correction tools, effective writing in mobile devices)
- computer lexicography (better dictionaries, larger dictionaries)
- machine translation (parallel corpora)
- statistics for enhancing NLP tools
What can we offer?
Ready-made tools for corpus building, management and effective search:
- Building: from own data/from the web, crawling, cleaning, deduplication
- Management: effective indexing in special DBMS
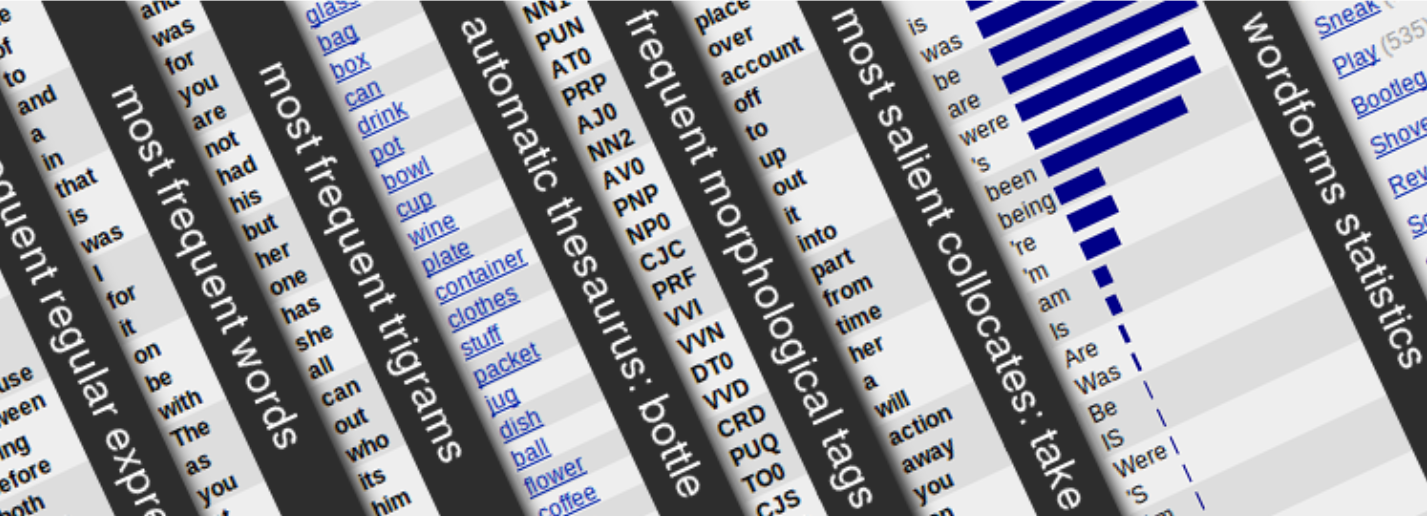
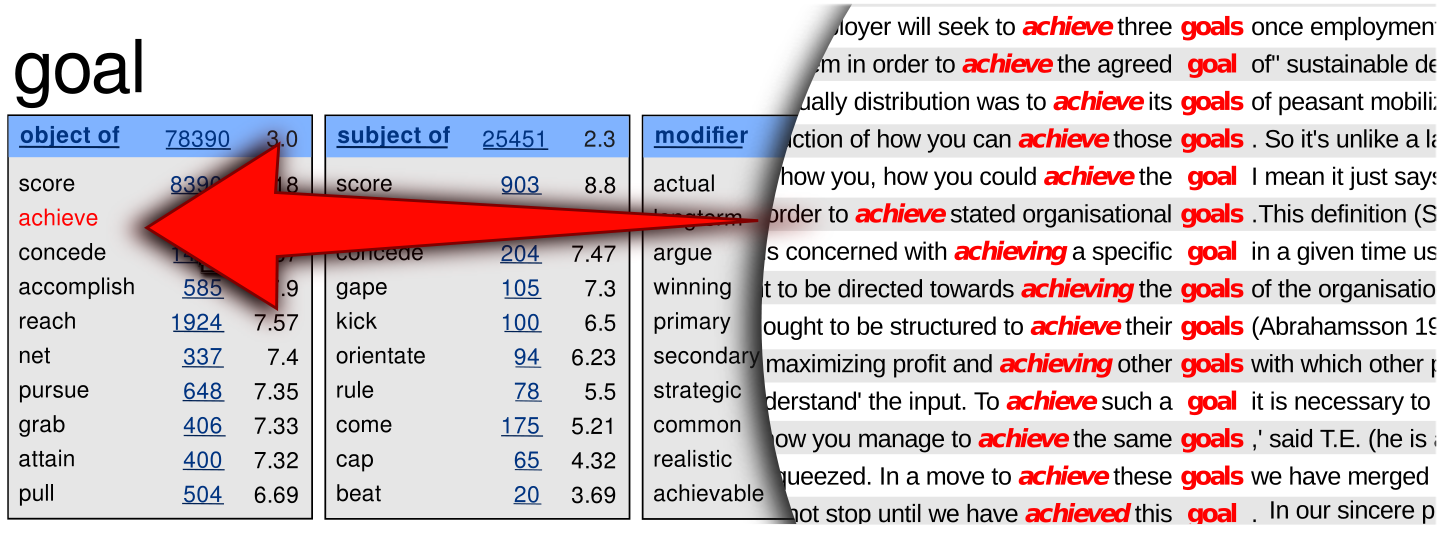
- Search: very fast evaluation of complex queries, keywords extraction, extraction of semantically related words, word sketches
Most of the tools are part of Sketch Engine, a product developed in collaboration with Lexical Computing Ltd.
Demo: Sketch Engine
Compare and contrast words visually

Build specialised corpora instantly from the Web

Thesaurus

Conclusions
Text corpora represent a valuable information source useful for many practical applications.
Corpora as text databases require special solutions that are fast and powerful.
There are number of tools developed in the NLP Centre for corpus building, management and efficient search.
Last modified 11 years ago
Last modified on Jun 5, 2014, 11:53:08 AM
Attachments (10)
- text.png (611.8 KB) - added by 11 years ago.
- goal.png (332.1 KB) - added by 11 years ago.
- what_is_corpus.png (76.0 KB) - added by 11 years ago.
- distribution.png (54.0 KB) - added by 11 years ago.
- corpus_langs.png (225.3 KB) - added by 11 years ago.
- query.png (364.9 KB) - added by 11 years ago.
- comparison.png (148.8 KB) - added by 11 years ago.
- corpus_build.png (471.3 KB) - added by 11 years ago.
- corpus_test.png (141.1 KB) - added by 11 years ago.
- corpora_size.png (26.5 KB) - added by 11 years ago.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}