About project.
This project is open source implementation of social network analysis system for pa026 class(Artificiall Intelligence project) at FI.MUNI.CZ. This project contains social network analyser on twitter, my main goal for creating this was interest learning of bulding web platform which can analyse textual data. So i made simple twitter search page where you can search tweets and it recognize sentiment and categories. You can clone this repository this way:
$ cd ~
$ git clone https://github.com/Cospel/pa026.git
Install/Download project to your home folder, as the makefile is currently working with it.
Setup project
This is example setup for ubuntu 14.10(basicaly you need to have python, django, rabbitmq, celery and libraries listed from setup rule in Makefile):
$: sudo make setup
$: make init_web
You can install rabbit-mq on debian like system with $: sudo apt-get install rabbitmq-server You can run it locally easy in debug, rabbitmq should be running($: service rabbitmq-server restart):
$: cd Website
$: export PYTHONPATH=~/pa026/Website/:~/pa026/
$: celery --app=Website.celery_app:app worker --loglevel=INFO
$: python manage.py runserver
Last command will run your webpage probably on localhost with port 8000. See the output from command, then you can open the page. Otherwise you can run it on your webserver for production for example with gunicorn, supervisor. This is more complicated way and demands some administration skills for linux.
Architecture
This projects consists of six modules:
- Config
- Crawler
- Database
- Miner
- Scripts
- Website
Config contains class for parsing xml document. In config module there is a xml with specifing twitter profiles with categories. Database modules are used for scripts, to store data for experiments in Scripts module.
Crawler is module with class TwitterCrawler which contains interface for downloading data from twitter. This class is based on tweepy library which is working with twitter api, with tokens that are generated from twitter for this application. There are methods for streaming data(streaming api), search data(search api) and it can be easily improve with just adding new methods.
Miner module contains main methods for parsing and cleaning text data, and learned classifiers for detecting sentiment and categories. Method text_parsing will go throug text/tweet and removes the url, punctuation, small words, shorten words(like cooool to cool) and so on. The main classifier method are get_sentiment and get_category which save to database predicted results. Classification is based on scikit-learn library, the classification pipeline which consists of CountVectorizer, TF-IDF and Classifier is loaded by pickle(class for data dumping). This classifier was trained by scrip 00011b from Scripts folder.
Scripts folder contains more than 12 scripts which are basicaly scripts for downloading data, manipulating data, training classifiers and so on.
The last module Website contains project in Django, this module represent ui-web interface client. There are three web applications Website, Manage, Twitter. Manage is for authentication of user(test user is admin:admin), caching sessions and User database table. Website app has basic settings for django project. Twitter application contains views for searching and analysing twitter data. Be aware that there is limitation on twitter api.
Django web application
Django data models
The web application currently works with two data models all of them are specified in models.py files. First model is User of the system, currently there is only one user after make init_web and that is:user:admin
password:admin
How are analytics computed?
Computing of twitter timeline(currently there are data downloaded trough search api and not timeline as I want to show results much faster, but it can be easily switch to timeline with change of method from TwitterCrawler) analysis is done through Celery tasks because the computing can take a few seconds, so the user doesn't need to wait for loading web page. The method which is computed behind the web application is decorated with @shared_task. When this method is called the Celery(Celery is an open source asynchronous task queue/job queue based on distributed message passing.) run this method. Celery needs some broker for messages, in this project I used the RabbitMQ which is recommended.
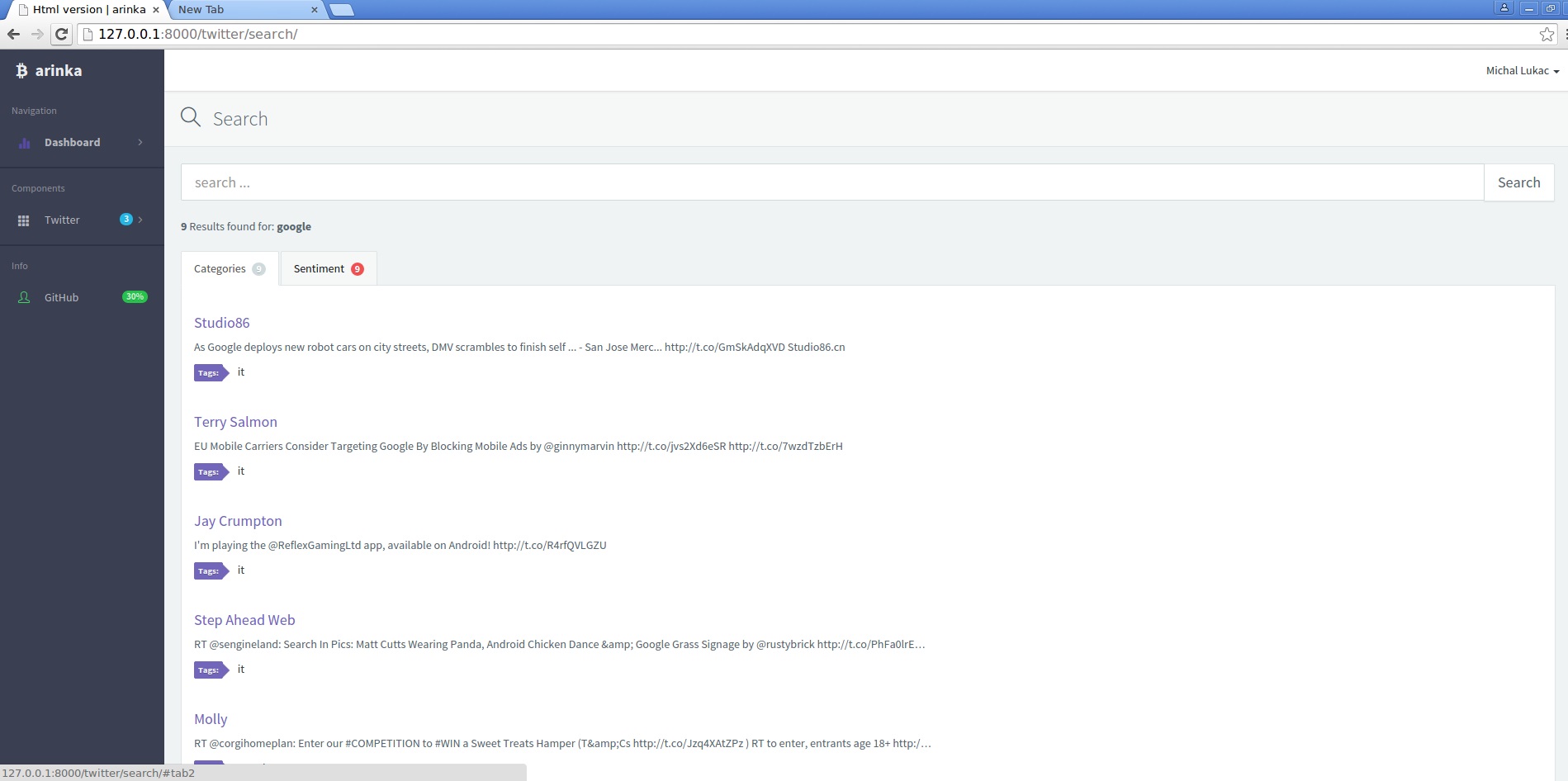
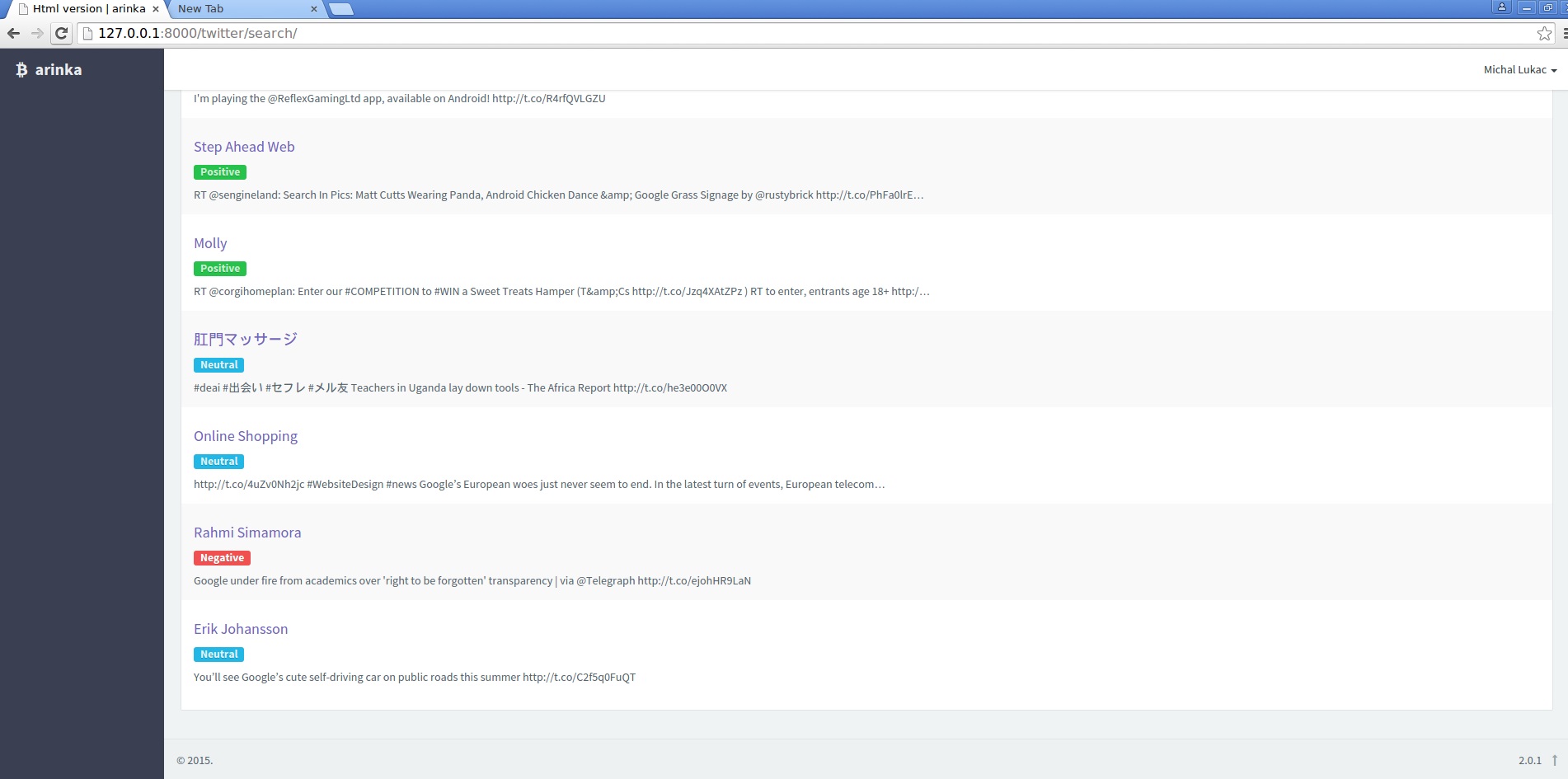
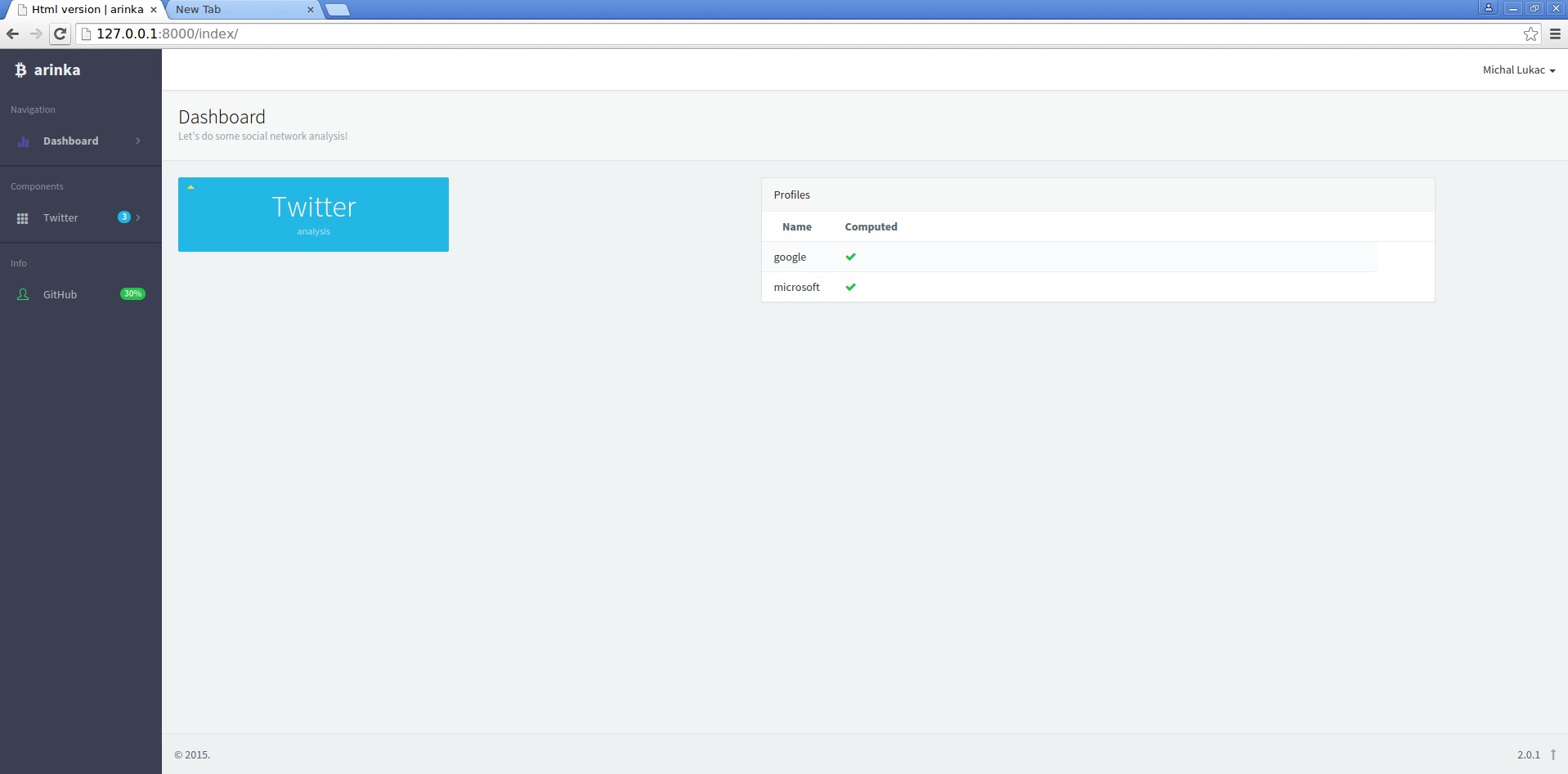
Screenshots
{kind=link}
{kind=link}
{kind=link}
There are three screenshots showing searching tweets and classifing them into categories, sentiment and there is also dashboard screenshot(main page).
Data
It is hard to obtain big amount of data through search api from twitter because of their restrictions. For the categories classifier I choose to create the twitterData.xml which contains several profiles with category. Script 00001b will go through this file and download <800 tweets from every of this profile. Only english tweets and tweets with more than 4 words were downloaded. Final training dataset contains cca 51000 tweets with eight categories. For example "IT" category contains data from microsoft, google, ... profiles. Ten percent of data was randomly chosen to test dataset 90 percent of data are in training data set. For test dataset i choose that every category will have 600 tweets. So the resulting test dataset contains 4800 tweets. Text of tweet can have missing some of the words because of preprocessing. If you need new/actual twitter dataset you can run script:
- $:python 00001_download.py
- $:python 00012_database_to_file.py
First script will download the data to sqlite db from twitterData.xml, you can extend this xml with new profile and categories. Second script will convert downloaded data to text file so you can easily use it in your experiments.
For the sentiment analysis I used the dataset from sentiment140.com. This dataset was collected by negative and positive emoticons.
Preprocessing data
One necessary/critical step in building machine learning systems is preprocessing data. This means that I go over downloaded tweet datasets and try to remove from words for example useless words. My function in Miner/NLP.py called text_parsing which does:- remove urls
- remove punctuation
- remove digits
- remove authors
- remove short words
- replace three or more of same characters with one
Evaluation of classifiers
I created classifiers for:
- Categories
- Sentiment
As library I used scikit-learn, numpy, scipy and gensim.
Category classifier
This is confusion matrix for MultinomialNB for test data set(histogram shows number of correct predictions for each category, max is 600):
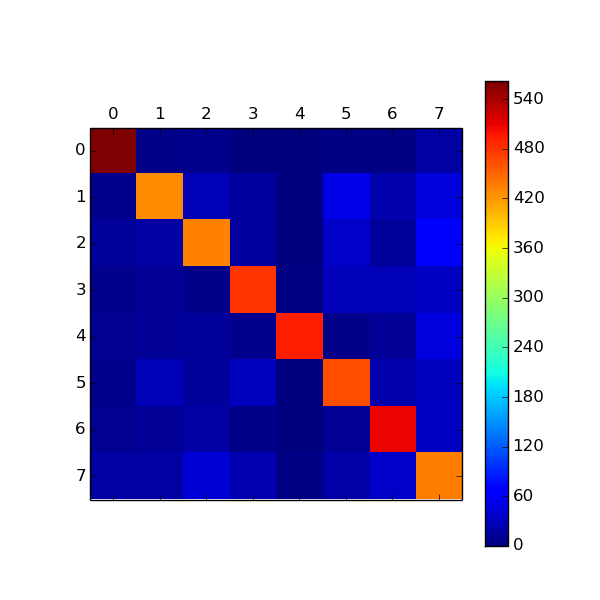
From the confusion matrix of logistic regression classifier we can see that it is easiest to determine first and last category. It is not suprise that these are categories for "it" and "adult" as it easy quite easy to determine tweets with "android", "microsoft" or sexual content. For the categories that are not easily rocgnized I created category "unknown" and this category was trained on picked profiles with various of topics("politics", "stories", "personal", "jokes",...).
Following table shows accuracy for various of classifiers:
| Classifier | word[bigram] | char_wb[range=4,6] |
| MultinomialNB | 0.804 | 0.787 |
| SVM | 0.768 | 0.756 |
| Logistic Reg | 0.804 | 0.813 |
| Random forest | 0.751 | 0.758 |
I trained classifiers with scikit-learn library, from which i picked Logistic regression, Random forrest(with 50 estimators), SVM, and multinomial naive bayes. In the table there is result for uni/bigram model and char model on range 4-6. Then the vectors were converted to TF-IDF which improves accuracy.
I tried also use Latent semantic analysis with tf-idf, but there were no satisfying results(lower then 60% for accuracy). If you want to create your custom models you can do this easily with scikit-learn pipeline with similar code:
svd_model = TruncatedSVD(n_components=num_topics,
algorithm='randomized',
n_iter=10, random_state=42)
clf = Pipeline([('vect', CountVectorizer(stop_words='english' , ngram_range=[1,2], analyzer='word', min_df=5)),
('tfidf', TfidfTransformer(use_idf=True,smooth_idf=True)),
('svd', svd_model), # you can delete this line to turn off LSI
('clf', SGDClassifier(alpha=1e-2)) ])
Sentiment classifier
My first experiments were with gensim and word2vec language model. However this doesn't work very well, so instead of word2vec I again choose algorithm like naive bayes and it accuracy was quite good. We need to know that dataset from sentiment140 is not best for learning because they automatically set category by emoticon in text(of course the emoticon was removed after that). I take randomly from training dataset about 8000 tweets and create dataset for testing my model. Final accuracy for naive bayes is 72.3 %.
Model with ngram 4-7 range of chars was better then simple ngram model. I think that it is because many tweets have typos in their words, so this will take only parts of the words which are more possible to be correct.
How to play with data
In folder Scripts there are data for category and sentiment classifier. Data are in data.tar.gz file. For extracting this file use command:
$:cd Scripts
$:tar -zxvf data.tar.gz
Then you can edit file 00011b or 00013(which train classifiers) and set variables train_file and test_file. So for example if you want to train sentiment classifier then you should change these variables to 'full1600000.txt' and 'test1600000.txt'. Run script this way to obtain results:
python 00011b_sec.py
What's next?
I'm looking forward to improve this project in future. The next steps/task what i want to do are:
- Create registration for user
- Move folders Config, Crawler, Database, Miner to new app folder in Website project. This is recommended in django framework due to imports.
- Add apache spark technology for analytics and e
- Improve sentiment analysis