
| Version 33 (modified by , 10 years ago) (diff) |
|---|
Někdo rozumí počítačům. Počítače nerozumí nikomu. Naučíme je to?
Information Extraction
Odpověď: Vyrovnáno.
Projekt Demagog.cz ji delší dobu mapuje výroky našich politiků. Přiřazení příznaku pravda/nepravda probíhá zatím manuálně.

S vhodnou bází dat by bylo možné na základě syntaktické a logické analýzy výroku o jeho pravdivosti rozhodnout automaticky.
Opinion Mining
Odpověď: Ano, dokonce bude mít radost, že se vám líbí ten nový iPhone / Samsung Galaxy / HTC / Sony Xperia / Huawei pitomý smartphone.
Dolování názorů je téma, kterému se poslední dobou věnuje mnoho lidí. Software pro dolování názorů využívá jak jazykových technik, tak například strojového učení.
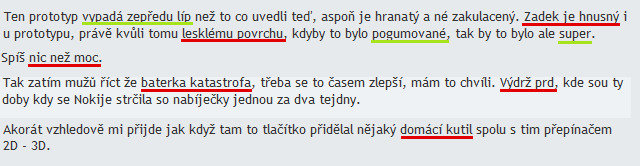
Sledováním diskusních fór a sociálních sítí lze dokonce zjistit, jak se oblíbenost jednotlivých telefonů mění v čase.
Knowledge Extraction
Odpověď: Ano.
Extrakce informací z textu je velmi žádaným tématem. V případě anglických textů se používají zpravidla jen statistické metody. Čeština, podobně jako jiné slovanské jazyky, má bohatou flexi (skloňování jmen a časování sloves), a proto je třeba před statistickým zpracováním určit základní tvary slov.
KOCOUR: To kuře je dobrý.
LISTER: No jo, fakt dobrý.
KRYTON: To není kuře, pánové.
KOCOUR: A co to je?
KRYTON: Ten mu, co jsme ho nali.
LISTER: Cože?
KRYTON: Připadalo mi to, jako hrozné mrhání ho tam nechat,
kdy by se tak bezvadně griloval.
RIMMER se chichotá.
KRYTON: Udělal jsem něco špatně? Nedostal jsem žádné hlášení o chybě.
Asi je to tím, že nemám čip svědomí a žádné morální imperativy,
které by mě vedly. Ale přilo mi logické, že kdy lidé jedí kuřata,
tak budou pojídat i svůj druh. Přece by si nezasedli pouze na kuřata.
Natural Language Generation
Odpověď: Ano.
Generování textů v přirozeném jazyce je celý vědní podobor. Vědecké prace vygenerované programem SciGen byly u několikrát přijaty na konference. Pro české a slovenské texty zatím software nemáme, a proto musí nebozí studenti za práce platit nebo je sami psát (zatím).

Corpus-Based Knowledge
Odpověď: Bůh ví 4,2578537320x častěji než čert.
Vytváříme obrovské soubory textů (jazykové korpusy), ze kterých se lingvisté o jazyku leccos dozvídají: která slova se používají často, málo často, často spolu, která slova jsou nová a co znamenají. Vývoj software, který umožňuje indexovat miliardy slov a pomocí regulárních výrazů v nich rychle vyhledávat, je informatická výzva.
Dictionaries
Odpověď: Aktivní slovní zásoba jedince v mateřském jazyce je asi 5000-10000 slov.
Prožít pěkný život lze i s mnohem méně než pěti tisíci slovy. Pasivní slovní zásoba je asi 5x rozsáhlejší. Měřením slovní zásoby (aktivní i pasivní) cizího jazyka můžete zjistit, jak dobře jazyk znáte. Lidé mají svá oblíbená slova, která jsou pro jejich mluvený nebo psaný projev charakteristická. Díky tomu můžeme poznat autora textu, případně zjistit, že je vrcholový sportovec. Tak určitě.

Attachments (28)
- demagog_zeman.png (74.2 KB) - added by 10 years ago.
- opinion.png (13.7 KB) - added by 10 years ago.
- scigen.PNG (62.1 KB) - added by 10 years ago.
- test_vocab.png (53.1 KB) - added by 10 years ago.
- vedet.png (25.0 KB) - added by 10 years ago.
- eliza.PNG (70.3 KB) - added by 10 years ago.
- bc.png (76.7 KB) - added by 10 years ago.
- myslim.png (75.6 KB) - added by 10 years ago.
- trees.png (39.2 KB) - added by 10 years ago.
- trees_alt.png (456.1 KB) - added by 10 years ago.
- books.png (241.2 KB) - added by 10 years ago.
- prase_s_nahrdelnikem.jpg (1.6 MB) - added by 10 years ago.
- ssc.PNG (57.3 KB) - added by 10 years ago.
- cz_accent.PNG (112.9 KB) - added by 10 years ago.
- nlp.fi.muni.cz_Artificial_Communication_Systems.pdf (181.1 KB) - added by 10 years ago.
- nlp.fi.muni.cz_Computer_Lexicography.pdf (166.3 KB) - added by 10 years ago.
- nlp.fi.muni.cz_Conceptual_Representation.pdf (170.9 KB) - added by 10 years ago.
- nlp.fi.muni.cz_Corpus_Engineering.pdf (1.3 MB) - added by 10 years ago.
- nlp.fi.muni.cz_Corpus-Based_Knowledge.pdf (144.2 KB) - added by 10 years ago.
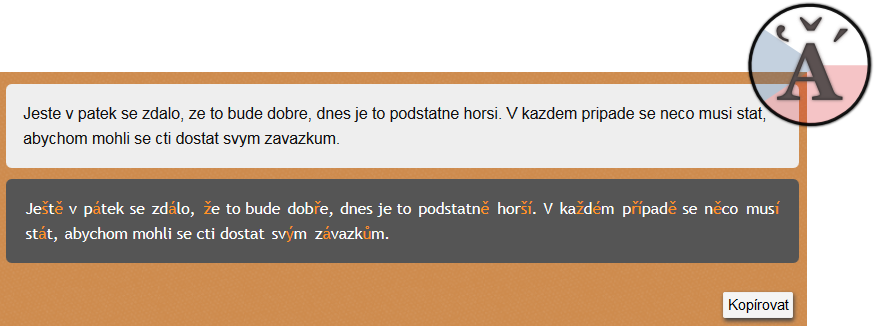
- nlp.fi.muni.cz_Diacritics_Restoration.pdf (234.8 KB) - added by 10 years ago.
- nlp.fi.muni.cz_Dictionaries.pdf (138.3 KB) - added by 10 years ago.
- nlp.fi.muni.cz_Gamification.pdf (198.6 KB) - added by 10 years ago.
- nlp.fi.muni.cz_Information_Extraction.pdf (180.7 KB) - added by 10 years ago.
- nlp.fi.muni.cz_Knowledge_Extraction.pdf (150.6 KB) - added by 10 years ago.
- nlp.fi.muni.cz_Language_Knowledge.pdf (1.8 MB) - added by 10 years ago.
- nlp.fi.muni.cz_Named_Entity_Recognition.pdf (445.2 KB) - added by 10 years ago.
- nlp.fi.muni.cz_Natural_Language_Generation.pdf (155.3 KB) - added by 10 years ago.
- nlp.fi.muni.cz_Opinion_Mining.pdf (134.8 KB) - added by 10 years ago.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Download in other formats:
Powered by Trac 1.2.3
By Edgewall Software.
Visit the Trac open source project at
http://trac.edgewall.org/