= Na čem pracujeme v NLP Centru? =
Centrum zpracování přirozeného jazyka se zaměřuje na získávání výsledků v oblastech informačních technologií a jazykovědy. Výsledky projektů jsou hojně publikovány na konferencích, Centrum ZPJ také spolupracuje s tuzemskými i zahraničními pracovišti podobného zaměření a studentům nabízí výměnné pobyty na partnerských univerzitách mimo republiku.
Vyzkoušejte si některé naše jazykové nástroje:
* [http://prirucka.ujc.cas.cz/ Internetová jazyková příručka]
* [http://nlp.fi.muni.cz/cz_accent/ CZ accent][[BR]] ''nástroj na doplňování diakritiky''
* [http://nlp.fi.muni.cz/%7Expopelk/xplain/ X-Plain][[BR]] ''hra Activity s počítačem''
* Majka ([http://nlp.fi.muni.cz/czech-morphology-analyser Czech],[http://nlp.fi.muni.cz/slovak-morphology-analyser Slovak],[http://nlp.fi.muni.cz/polish-morphology-analyser Polish],[http://nlp.fi.muni.cz/english-morphology-analyser English]) [http://nlp.fi.muni.cz/projekty/wwwajka (webové rozhraní)] [[BR]] ''morfologický analyzátor''
* [http://nlp.fi.muni.cz/projekty/wwwsynt/query.cgi Synt] a [http://nlp.fi.muni.cz/projekty/set/ SET] ''syntaktické analyzátory''
* [https://the.sketchengine.co.uk/open/ Vyhledávání v textových korpusech]
''Bližší informace následují níže, tematicky seskupené do následujících kapitol:''
* [#Korpusy Korpusy]
* [[MainTopics#dict| Slovníky]]
* [[MainTopics#morph| Morfologie]]
* [[MainTopics#syntan| Syntaktická analýza]]
* [[MainTopics#semant| Sémantika]]
== Korpusy == #Korpusy
{{{
#!html
 }}}
[[Image(/trac/research/attachment/wiki/cs/MainTopics/corpora.png, align=right)]]
Korpus je kolekce textových dat v elektronické podobě. Jako významný zdroj lingvistických dat slouží korpusy ke zkoumání mnoha frekvenčních jevů jazyka a v současnosti jsou již neodmyslitelným nástrojem v oblasti NLP. Kromě korpusů obsahujících libovolné texty, se vytvářejí i jiné pro zvláštní účely, např. značkované, doménové, mluvené nebo chybové.
Korpusy se používají při zkoumání a konstrukci gramatik přirozených jazyků. Dále mohou být užitečné při tvorbě gramatického korektoru, při výběru hesel do slovníků, nebo jako zdroj dat pro automatickou kategorizaci textů s použitím metod strojového učení. Paralelní korpusy jsou tvořeny obsahově totožnými a zarovnanými texty v různých jazycích. Uplatňují se zejména v oblastech zjednoznačňování významů a strojového překladu.
V dnešní době je nejdůležitějším zdrojem korpusových dat Internet. Aby bylo možné data získaná z webu použít pro jazykové účely, je velmi vhodné je předzpracovat: například programem '''jusText''' na odstranění netextových částí webových stránek, nástrojem '''onion''', který odstraňuje duplicitní části textu, nebo programem '''chared''' na rozpoznávání kódování textů. Velmi užitečným je také oblíbený systém '''gensim''', který umožňuje určit témata, o kterých se v píše v daném textu.
V NLP Centru byla vytvořena kompletní sada nástrojů pro tvorbu a správu korpusů '''Corpus Architect'''. Tyto korpusy mohou obsahovat i více než 100 miliard slovních pozic.
{{{
#!html
}}}
[[Image(/trac/research/raw-attachment/wiki/cs/MainTopics/metatrans.png, align=left)]]
''Související projekty:''
* [http://nlp.fi.muni.cz/trac/noske NoSketch Engine]
* [http://ske.fi.muni.cz/ Lokální instalace Sketch Engine pro Masarykovu univerzitu]
* [http://www.sketchengine.co.uk/ Sketch Engine]
* [http://nlp.fi.muni.cz/projekty/cpa/ CPA]
* [http://nlp.fi.muni.cz/projekty/justext/ jusText]
* [http://code.google.com/p/onion/ onion]
* [http://code.google.com/p/chared/ chared]
* [http://radimrehurek.com/gensim/index.html Gensim]
''Související články:''
* [[UvodDoKorpusoveLingvistiky| Úvod do korpusové lingvistiky]]
== Slovníky == #dict
{{{
#!html
}}}
[[Image(/trac/research/attachment/wiki/cs/MainTopics/corpora.png, align=right)]]
Korpus je kolekce textových dat v elektronické podobě. Jako významný zdroj lingvistických dat slouží korpusy ke zkoumání mnoha frekvenčních jevů jazyka a v současnosti jsou již neodmyslitelným nástrojem v oblasti NLP. Kromě korpusů obsahujících libovolné texty, se vytvářejí i jiné pro zvláštní účely, např. značkované, doménové, mluvené nebo chybové.
Korpusy se používají při zkoumání a konstrukci gramatik přirozených jazyků. Dále mohou být užitečné při tvorbě gramatického korektoru, při výběru hesel do slovníků, nebo jako zdroj dat pro automatickou kategorizaci textů s použitím metod strojového učení. Paralelní korpusy jsou tvořeny obsahově totožnými a zarovnanými texty v různých jazycích. Uplatňují se zejména v oblastech zjednoznačňování významů a strojového překladu.
V dnešní době je nejdůležitějším zdrojem korpusových dat Internet. Aby bylo možné data získaná z webu použít pro jazykové účely, je velmi vhodné je předzpracovat: například programem '''jusText''' na odstranění netextových částí webových stránek, nástrojem '''onion''', který odstraňuje duplicitní části textu, nebo programem '''chared''' na rozpoznávání kódování textů. Velmi užitečným je také oblíbený systém '''gensim''', který umožňuje určit témata, o kterých se v píše v daném textu.
V NLP Centru byla vytvořena kompletní sada nástrojů pro tvorbu a správu korpusů '''Corpus Architect'''. Tyto korpusy mohou obsahovat i více než 100 miliard slovních pozic.
{{{
#!html
}}}
[[Image(/trac/research/raw-attachment/wiki/cs/MainTopics/metatrans.png, align=left)]]
''Související projekty:''
* [http://nlp.fi.muni.cz/trac/noske NoSketch Engine]
* [http://ske.fi.muni.cz/ Lokální instalace Sketch Engine pro Masarykovu univerzitu]
* [http://www.sketchengine.co.uk/ Sketch Engine]
* [http://nlp.fi.muni.cz/projekty/cpa/ CPA]
* [http://nlp.fi.muni.cz/projekty/justext/ jusText]
* [http://code.google.com/p/onion/ onion]
* [http://code.google.com/p/chared/ chared]
* [http://radimrehurek.com/gensim/index.html Gensim]
''Související články:''
* [[UvodDoKorpusoveLingvistiky| Úvod do korpusové lingvistiky]]
== Slovníky == #dict
{{{
#!html
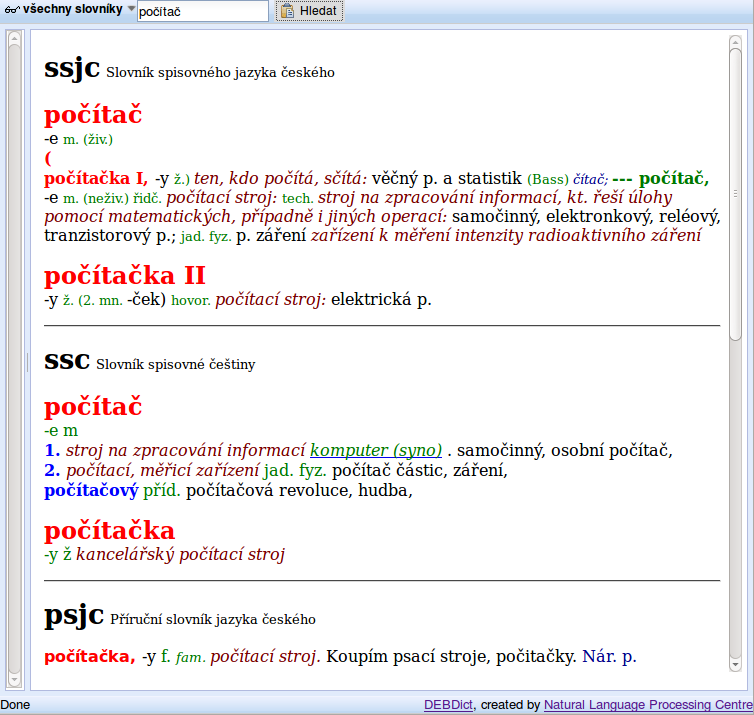 }}}
Slovníky jsou odjakživa základní pomůckou jazykovědců. Ovšem práce s nimi v papírové podobě je zdlouhavá a nepraktická. Proto jedním z prvních projektů CZPJ byla digitalizace klasických slovníků spisovného jazyka a vývoj souboru pokročilých nástrojů pro zpracování slovníkových dat označovaných souhrnně jako lexikografická stanice. Jedná se o systém, který umožní odbornému uživateli pohodlný přístup k mnoha různým lingvistickým zdrojům a poskytne mu aplikační prostředí pro vyhledávání a editaci dat.
Jedním z našich slovníkově zaměřených projektů je vývoj '''''platformy DEB''''', která při použití architektury klient-server výše uvedené požadavky splňuje. Příkladem klientské aplikace je prohlížeč slovníků '''''DEBDict''''', ve kterém je kromě digitalizovaných slovníků k dispozici také několik encyklopedií, onomastický a frazeologický slovník. Aplikace pro DEB se vyvíjejí v jazyku XUL a jsou dostupné jako rozšíření pro webový prohlížeč Firefox. [[BR]]
''Související projekty:''
* [http://nlp.fi.muni.cz/projekty/deb2/ DEB II]
* [http://nlp.fi.muni.cz/projekty/deb2/debdict/ DEBDict]
* [http://nlp.fi.muni.cz/projekty/deb2/#debvisdic DEBVisDic]
* [http://nlp.fi.muni.cz/cs/VerbaLex VerbaLex]
* [http://metatrans.fi.muni.cz/ MetaTrans]
* [http://nlp.fi.muni.cz/projekty/cpa/ CPA]
== Morfologie == #morph
{{{
#!html
}}}
Slovníky jsou odjakživa základní pomůckou jazykovědců. Ovšem práce s nimi v papírové podobě je zdlouhavá a nepraktická. Proto jedním z prvních projektů CZPJ byla digitalizace klasických slovníků spisovného jazyka a vývoj souboru pokročilých nástrojů pro zpracování slovníkových dat označovaných souhrnně jako lexikografická stanice. Jedná se o systém, který umožní odbornému uživateli pohodlný přístup k mnoha různým lingvistickým zdrojům a poskytne mu aplikační prostředí pro vyhledávání a editaci dat.
Jedním z našich slovníkově zaměřených projektů je vývoj '''''platformy DEB''''', která při použití architektury klient-server výše uvedené požadavky splňuje. Příkladem klientské aplikace je prohlížeč slovníků '''''DEBDict''''', ve kterém je kromě digitalizovaných slovníků k dispozici také několik encyklopedií, onomastický a frazeologický slovník. Aplikace pro DEB se vyvíjejí v jazyku XUL a jsou dostupné jako rozšíření pro webový prohlížeč Firefox. [[BR]]
''Související projekty:''
* [http://nlp.fi.muni.cz/projekty/deb2/ DEB II]
* [http://nlp.fi.muni.cz/projekty/deb2/debdict/ DEBDict]
* [http://nlp.fi.muni.cz/projekty/deb2/#debvisdic DEBVisDic]
* [http://nlp.fi.muni.cz/cs/VerbaLex VerbaLex]
* [http://metatrans.fi.muni.cz/ MetaTrans]
* [http://nlp.fi.muni.cz/projekty/cpa/ CPA]
== Morfologie == #morph
{{{
#!html
 }}}
Morfologická analýza je základním prostředkem zkoumání přirozeného jazyka a zabývá se rozlišováním a generováním správných gramatických tvarů slovních výrazů, které vzniknou skloňováním a časováním. Výsledkem je sada značek, které popisují gramatické kategorie daného tvaru, zejména pak základní tvar (lemma) a slovní vzor. Automatické rozlišení tvaru slova ve volném textu lze využít při vývoji gramatického korektoru, jako pomůcka při značkování korpusů nebo při poloautomatickém vytváření slovníků. Největší problém v této oblasti je morfologická desambiguace (zjednoznačňování gramatické značky) - tedy jak automaticky rozlišit, zda slovo "jedu" označuje sloveso nebo podstatné jméno.
V CZPJ byl vytvořen obecný morfologický analyzátor pro češtinu '''''"Majka"''''' pokrývající slovní zásobu s více než 6 milióny slovních tvarů. Díky němu vznikly podobný analyzátor pro slovenštinu, gramatický korektor '''''"fispell"''''', převodník ascii textu na text s diakritikou '''''"czaccent"''''' nebo interaktivní rozhraní pro IM protokol Jabber.
''Související projekty:''
* [http://nlp.fi.muni.cz/czech-morphology-analyser Majka] [http://nlp.fi.muni.cz/projekty/wwwajka (webové rozhraní)]
* [http://nlp.fi.muni.cz/ma/free.html Fajka (analyzátor s volnou versí dat)]
* [http://nlp.fi.muni.cz/cz_accent/ CZ accent]
== Syntaktická analýza == #syntan
{{{
#!html
}}}
Morfologická analýza je základním prostředkem zkoumání přirozeného jazyka a zabývá se rozlišováním a generováním správných gramatických tvarů slovních výrazů, které vzniknou skloňováním a časováním. Výsledkem je sada značek, které popisují gramatické kategorie daného tvaru, zejména pak základní tvar (lemma) a slovní vzor. Automatické rozlišení tvaru slova ve volném textu lze využít při vývoji gramatického korektoru, jako pomůcka při značkování korpusů nebo při poloautomatickém vytváření slovníků. Největší problém v této oblasti je morfologická desambiguace (zjednoznačňování gramatické značky) - tedy jak automaticky rozlišit, zda slovo "jedu" označuje sloveso nebo podstatné jméno.
V CZPJ byl vytvořen obecný morfologický analyzátor pro češtinu '''''"Majka"''''' pokrývající slovní zásobu s více než 6 milióny slovních tvarů. Díky němu vznikly podobný analyzátor pro slovenštinu, gramatický korektor '''''"fispell"''''', převodník ascii textu na text s diakritikou '''''"czaccent"''''' nebo interaktivní rozhraní pro IM protokol Jabber.
''Související projekty:''
* [http://nlp.fi.muni.cz/czech-morphology-analyser Majka] [http://nlp.fi.muni.cz/projekty/wwwajka (webové rozhraní)]
* [http://nlp.fi.muni.cz/ma/free.html Fajka (analyzátor s volnou versí dat)]
* [http://nlp.fi.muni.cz/cz_accent/ CZ accent]
== Syntaktická analýza == #syntan
{{{
#!html
 }}}
Úkolem syntaktické analýzy je rozpoznat, zda vstupní textový řetězec je větou v daném (přirozeném) jazyce. V kladném případě je výsledkem analýzy syntaktická struktura věty, například v podobě derivačního stromu. Cílem syntaktické analýzy je, aby počítač "porozuměl" gramatice přirozeného jazyka. Toho lze využít např. při vývoji syntaktického korektoru na opravu interpunkce, dialogového systému pro komunikaci v přirozeném jazyce nebo jako jeden z nástrojů pro realizaci strojového překladu. Čeština se svou bohatou ohebností (flexí) a volným slovosledem patří k nejobtížněji analyzovatelným jazykům, jelikož vyžaduje mnohem více pravidel gramatiky, než jiné jazyky.
NLP Centrum vyvíjí několik syntaktických analyzátorů. Syntaktický analyzátor '''synt''' je založen na české metagramatice doplněné o sémantické akce a kontextová omezení. '''SET''' je oblíbený syntaktický analyzátor založený na rozpoznávání vzorů. Oba tyto systémy dosahují přesnost až 90%. Pro výukové účely existuje jednoduchý analyzátor '''''Zuzana'''''.
''Související projekty:''
* [http://nlp.fi.muni.cz/projekty/wwwsynt/ Synt]
* [http://nlp.fi.muni.cz/projekty/set/ SET]
* [http://nlp.fi.muni.cz/projekty/zuzana/ Zuzana]
== Sémantika == #semant
{{{
#!html
}}}
Úkolem syntaktické analýzy je rozpoznat, zda vstupní textový řetězec je větou v daném (přirozeném) jazyce. V kladném případě je výsledkem analýzy syntaktická struktura věty, například v podobě derivačního stromu. Cílem syntaktické analýzy je, aby počítač "porozuměl" gramatice přirozeného jazyka. Toho lze využít např. při vývoji syntaktického korektoru na opravu interpunkce, dialogového systému pro komunikaci v přirozeném jazyce nebo jako jeden z nástrojů pro realizaci strojového překladu. Čeština se svou bohatou ohebností (flexí) a volným slovosledem patří k nejobtížněji analyzovatelným jazykům, jelikož vyžaduje mnohem více pravidel gramatiky, než jiné jazyky.
NLP Centrum vyvíjí několik syntaktických analyzátorů. Syntaktický analyzátor '''synt''' je založen na české metagramatice doplněné o sémantické akce a kontextová omezení. '''SET''' je oblíbený syntaktický analyzátor založený na rozpoznávání vzorů. Oba tyto systémy dosahují přesnost až 90%. Pro výukové účely existuje jednoduchý analyzátor '''''Zuzana'''''.
''Související projekty:''
* [http://nlp.fi.muni.cz/projekty/wwwsynt/ Synt]
* [http://nlp.fi.muni.cz/projekty/set/ SET]
* [http://nlp.fi.muni.cz/projekty/zuzana/ Zuzana]
== Sémantika == #semant
{{{
#!html
 }}}
Sémantická a pragmatická analýza jsou nejkomplexnější úrovně zpracování přirozeného jazyka, protože využívají všechny výše zmíněné disciplíny. Prubířským kamenem je zde strojový překlad, který s uspokojivými výsledky pro češtinu neexistuje.
Jedním z dlouhodobých projektů CZPJ je využití '''''transparentní intenzionální logiky (TIL)''''' jako jazyka pro sémantickou reprezentaci znalostí a transformačního jazyka v procesu automatického překladu. V současné fázi je reálné zpracovávat omezené znalosti v jednodušší podobě - experimentuje se se strojovým překladem nad určitou doménou, např. úředních dokumentů nebo počasí, nebo s polomechanickým překladem mezi blízkými jazyky, což jsou problémy řádově snažší. Při tom se využívají korpusy, sémantické sítě a elektronické slovníky.
V oblasti reprezentace významů a znalostí můžeme zmínit významnou spoluúčast členů centra v evropských projektech '''''EuroWordNet''''' a '''''Balkanet''''', které byly zaměřeny na budování vícejazyčné sémantické sítě typu '''''WordNet'''''. [[BR]]
''Související projekty:''
* [http://nlp.fi.muni.cz/projekty/deb2/#debvisdic DEBVisDic]
* [http://www.fi.muni.cz/%7Ehales/disert/ Logická analýza české věty v TIL]
* [http://nlp.fi.muni.cz/projekty/visualbrowser/ Visual Browser]
* [http://radimrehurek.com/gensim/index.html Gensim]
''Animovaná ukázka Visual Browseru:''
* [cs/main_topics/VlDemoGif ve formátu GIF (zjednodušená)]
== Další informace ==
* [[Specializace| Předměty specializace Zpracování přirozeného jazyka]]
* [http://nlp.fi.muni.cz/projekty/ Seznam vybraných projektů CZPJ]
* [https://nlp.fi.muni.cz/nlpis/baliky.php Aktuálně nabízená témata diplomových a bakalářských prací]
* [[Zajimave| Zajímavé texty o zpracování přirozeného jazyka]]
}}}
Sémantická a pragmatická analýza jsou nejkomplexnější úrovně zpracování přirozeného jazyka, protože využívají všechny výše zmíněné disciplíny. Prubířským kamenem je zde strojový překlad, který s uspokojivými výsledky pro češtinu neexistuje.
Jedním z dlouhodobých projektů CZPJ je využití '''''transparentní intenzionální logiky (TIL)''''' jako jazyka pro sémantickou reprezentaci znalostí a transformačního jazyka v procesu automatického překladu. V současné fázi je reálné zpracovávat omezené znalosti v jednodušší podobě - experimentuje se se strojovým překladem nad určitou doménou, např. úředních dokumentů nebo počasí, nebo s polomechanickým překladem mezi blízkými jazyky, což jsou problémy řádově snažší. Při tom se využívají korpusy, sémantické sítě a elektronické slovníky.
V oblasti reprezentace významů a znalostí můžeme zmínit významnou spoluúčast členů centra v evropských projektech '''''EuroWordNet''''' a '''''Balkanet''''', které byly zaměřeny na budování vícejazyčné sémantické sítě typu '''''WordNet'''''. [[BR]]
''Související projekty:''
* [http://nlp.fi.muni.cz/projekty/deb2/#debvisdic DEBVisDic]
* [http://www.fi.muni.cz/%7Ehales/disert/ Logická analýza české věty v TIL]
* [http://nlp.fi.muni.cz/projekty/visualbrowser/ Visual Browser]
* [http://radimrehurek.com/gensim/index.html Gensim]
''Animovaná ukázka Visual Browseru:''
* [cs/main_topics/VlDemoGif ve formátu GIF (zjednodušená)]
== Další informace ==
* [[Specializace| Předměty specializace Zpracování přirozeného jazyka]]
* [http://nlp.fi.muni.cz/projekty/ Seznam vybraných projektů CZPJ]
* [https://nlp.fi.muni.cz/nlpis/baliky.php Aktuálně nabízená témata diplomových a bakalářských prací]
* [[Zajimave| Zajímavé texty o zpracování přirozeného jazyka]]